“Even when the data has made it into a database, it is not safe… which bring us, finally, to Microsoft Excel.” - Matt Parker
¶ Introduction aux bases de données
¶ Données vs Informations
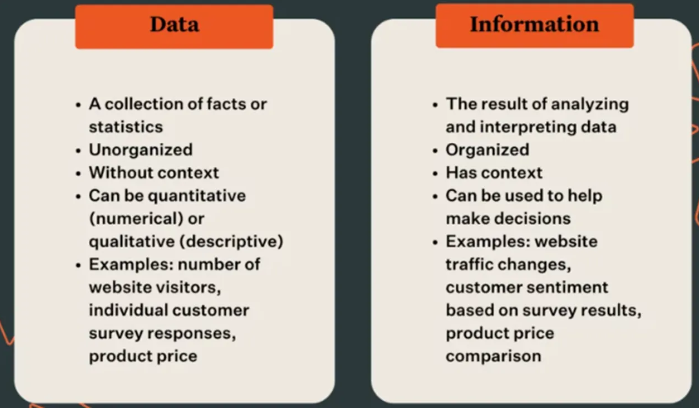
Les données (data) sont des éléments bruts, des faits ou des chiffres isolés qui, seuls, n'ont pas forcément de sens. Par exemple : "23,5", "Paris", "bleu" sont des données. L'information, c'est le résultat qu'on obtient quand on organise, analyse et contextualise les données pour leur donner du sens. Par exemple : "La température à Paris est de 23,5°C" devient une information car ces données sont structurées et apportent une compréhension.
Pour illustrer avec une analogie simple :
- Les données sont comme les ingrédients bruts d'une recette (farine, œufs, sucre...)
- L'information serait le gâteau final, où ces ingrédients sont assemblés de façon cohérente pour créer quelque chose d'utile
Caractéristiques principales :
- Données : brutes, isolées, sans contexte
- Information : structurée, contextualisée, porteuse de sens
L’indice BigMac est une donnée ou une information?
¶ Qu’est-ce qu’une base de données?
En informatique, une base de données (« BD » ou « BdD ») est un lot d’informations stockées dans un dispositif informatique. Un BD doit permette de manipuler facilement les données. La manipulation de données comprends:
- La recherche rapide
- La modification
- La suppression
- La mise-à jour
- L’analyse
Dans le monde informatique, une BD est représenté par l’image d’un cylindre comme ci-dessous
Question: Est-ce qu’un fichier texte peut-être considéré comme une BD?
¶ Pourquoi une base de données?
Une BD est nécessaire afin de conserver de l‘information de façon durable (persistance). Plus spécifiquement, la BD va assurer:
- Sécurité et contrôle
- Performance et efficacité
- Organisation et cohérence
¶ Un exemple de BO (bottin)
Ceci pourrait être un exemple de base de donnée:
| Nom | Prénom | Numéro |
| Ali | Mohammed | 514-333-2222 |
| Cartier | Jacques | 514-444-5555 |
| Colomb | Christophe | 438-123-4567 |
| Laviolette | Jacques | 450-321-6547 |
| Madeleine | Marie | 514-998-9888 |
| Zulu | Pablo | 514-999-9999 |
Questions:
- Tous les nom commencant par ‘M’?
- Les numéros du grand Montréal (514)?
- Combien de ‘Pablo’ dans le bottin?
- Nom avec 3 lettres seulement?
- Changer le numéro de telephone?
¶ Type de base de données

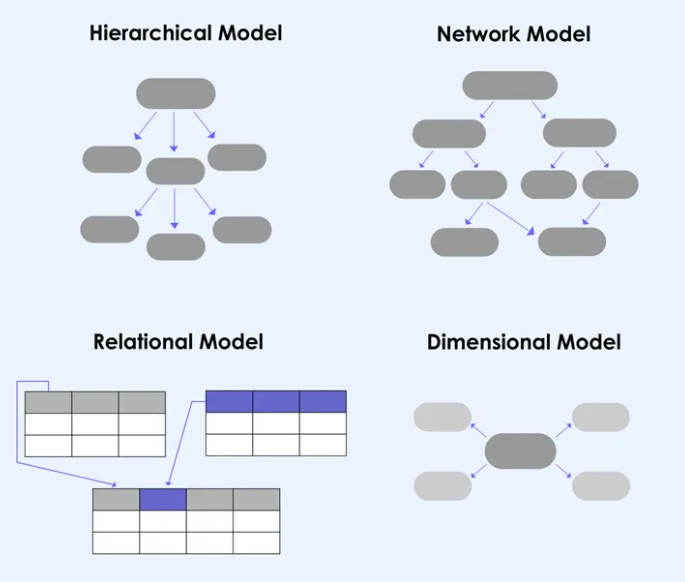
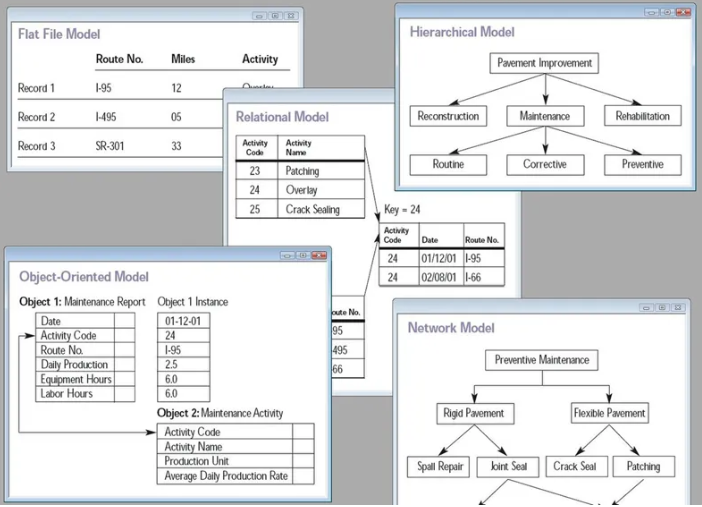
Question: Avez-vous un exemple de BD hiérarchique?
¶ Un peu d’histoire
Modèle Hiérarchique (1960) : Les premières bases de données étaient basées sur le modèle hiérarchique. Le système de gestion de base de données (SGBD) IMS (Information Management System), développé par IBM dans les années 1960, est un exemple de ce modèle. Les données étaient organisées sous forme d'arborescence, mais cela était souvent complexe à gérer.
Modèle en Réseau (1960-1970) : Le modèle en réseau a été introduit pour résoudre certaines des limitations du modèle hiérarchique. Le système CODASYL (Conference on Data Systems Languages) et son langage de requête DML (Data Manipulation Language) sont des exemples de cette époque. Cependant, la complexité persistait.
Modèle Relationnel (1970) : L'année 1970 a été marquée par la publication du célèbre document "A Relational Model of Data for Large Shared Data Banks" par Edgar Codd, qui a jeté les bases du modèle relationnel. Codd a introduit des concepts tels que les tables, les clés primaires et les clés étrangères. Le SGBD relationnel IBM System R et, plus tard, Oracle Database, ont joué un rôle clé dans la popularisation de ce modèle.
Développement de SQL (1970) : Le langage SQL (Structured Query Language) a été développé par IBM dans les années 1970, basé sur les travaux d'Edgar Codd. SQL est devenu le langage standard pour interagir avec les bases de données relationnelles et est toujours largement utilisé aujourd'hui.
Systèmes de Gestion de Bases de Données Relationnelles (SGBDR) (années 1980) : Les années 1980 ont vu l'émergence de nombreux SGBDR commerciaux tels qu'Oracle, IBM DB2, Microsoft SQL Server, et MySQL. Ces systèmes ont contribué à populariser l'utilisation des bases de données relationnelles dans le monde entier.
Normalisation des Bases de Données (années 1970-1980) : Les principes de normalisation ont été développés pour guider la conception de bases de données afin de réduire la redondance et d'améliorer l'intégrité des données. Les formes normales (1NF, 2NF, 3NF, etc.) sont utilisées pour organiser les données de manière optimale.
Systèmes de Gestion de Bases de Données Objets (SGBDO) (années 1990) : Les bases de données orientées objet sont apparues dans les années 1990, cherchant à combiner les concepts des bases de données relationnelles avec la programmation orientée objet. Des systèmes tels qu'ObjectStore et db4o ont été développés pour prendre en charge ces modèles.
Émergence des Bases de Données NoSQL (années 2000) : Avec l'explosion des données non structurées et la nécessité de gérer des volumes massifs de données, les bases de données NoSQL ont émergé. Ces systèmes, tels que MongoDB, Cassandra et Couchbase, offrent des modèles de données flexibles et évolutifs.
Cloud et Bases de Données (années 2010) :
Les bases de données dans le cloud sont devenues de plus en plus populaires, permettant un accès et une gestion des données à l'échelle mondiale. Des services de bases de données managés, tels que Amazon RDS et Azure SQL Database, ont simplifié le déploiement et la maintenance des bases de données
¶ SQL
SQL est l'abréviation de Structured Query Language (langage de requête structuré en français), et c'est un langage de programmation utilisé pour gérer et manipuler des bases de données relationnelles. Il permet aux utilisateurs de créer, modifier et interroger des bases de données en utilisant des commandes spécifiques.
| Langage: Français | Langage: SQL |
| Trouver tous les usagers? | SELECT * FROM Users; |
| Trouver tous les usagers de 18 ans et plus? | SELECT * FROM Users WHERE Age >= 18; |
¶ SGBD ou DataBase Management System (DBMS)
SGBD est l'acronyme de "Système de Gestion de Base de Données". Il s'agit d'un logiciel informatique utilisé pour stocker, organiser et gérer des données.
Il permet de manipuler des données de manière structurée et de manière à faciliter leur utilisation ultérieure.
Un SGBD fournit une interface pour la gestion des données, qui peut inclure des fonctions pour la création de tables, l'ajout, la modification et la suppression de données, ainsi que des fonctions pour effectuer des requêtes pour extraire des informations de la base de données. Il peut également offrir des fonctionnalités avancées telles que la gestion des transactions, la gestion de la sécurité, la sauvegarde et la récupération de données, la réplication de données, etc.
¶ SGBDR
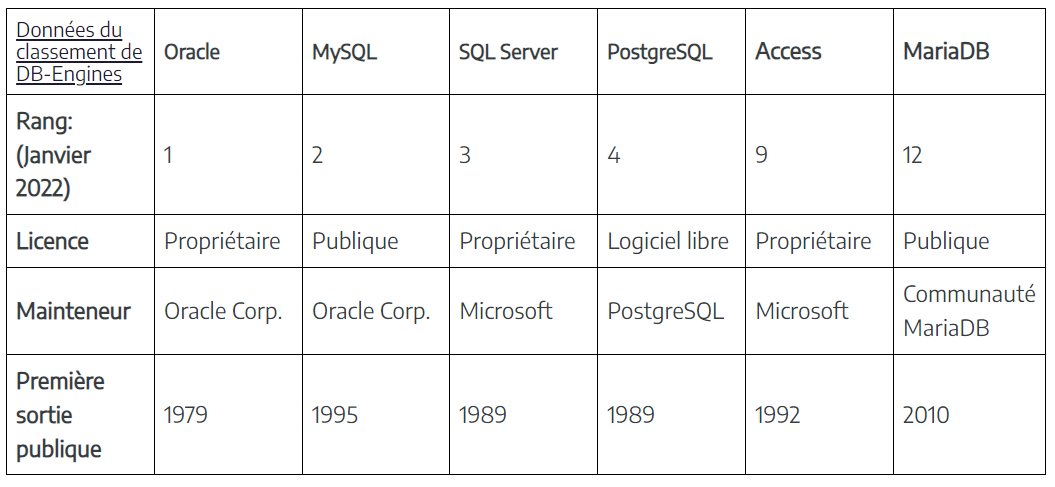
Un SGBDR est un SGBD spécialisé dans les BD relationnelles. Un SGBDR (Système de Gestion de Base de Données Relationnelle) est un logiciel qui permet de stocker, organiser et gérer des données dans des tables liées entre elles par des relations, tout en assurant leur cohérence, leur sécurité et leur accessibilité via le langage SQL. Il existent plusieurs SGBDR: MySQL, Microsoft SQL, PostgreSQL, SQLite, OracleDB, SQLite, MariaDB…

Ces SGBDR se différencient par :
- Coût
- Performance
- Facilité d'utilisation
- Fonctionnalités
- Support
- Cas d'usage
Tous ces SGBDR utilisent le langage SQL
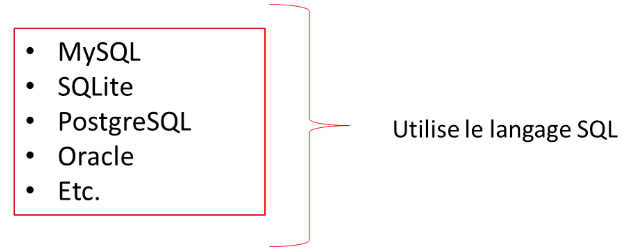
Les commandes sont donc les mêmes dans chaque environnements (voir SQL Standards):
| Langage: Français | Langage: SQL |
|---|---|
| Trouver tous les usagers? | SELECT * FROM Users; |
¶ Notion de Client/Serveur
La plupart des SGBD sont basés sur un modèle client-serveur ;
- Le serveur est le conteneur stockant les fichiers de la base de données (local ou distant, sécurisé ou non)
- Le client est l’interface (ligne de commande ou graphique) permettant d’interroger/manipuler les données du serveur à l’aide du langage SQL
- Le client se connecte au serveur en identifiant l’hôte, le nom de l’utilisateur et son mot de passe
¶ Exemple de solution sur le cloud
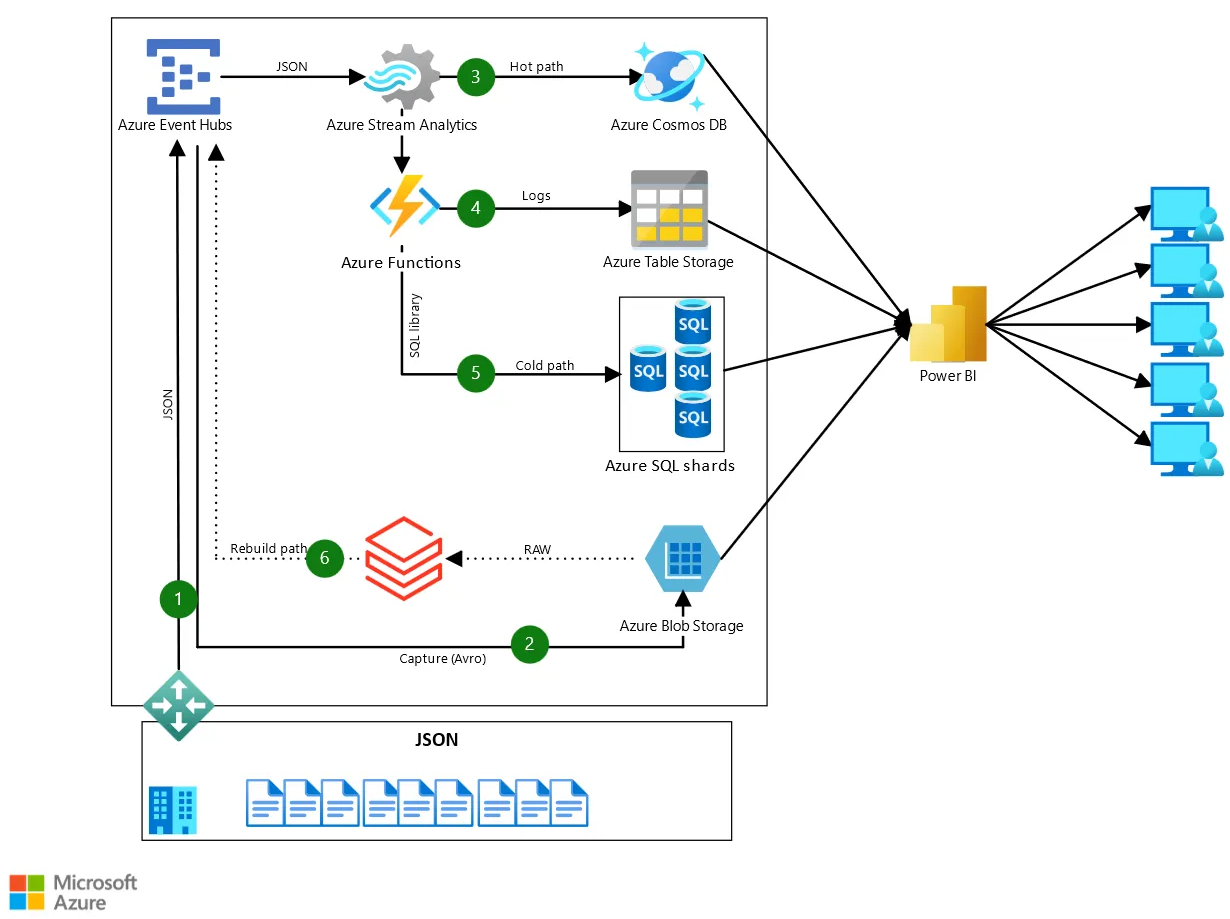
¶ Solution infonuagique
¶ Schéma d’une BD (ex.: Wikipédia)

¶ Installation de MySQL
¶ Installation de MySQL
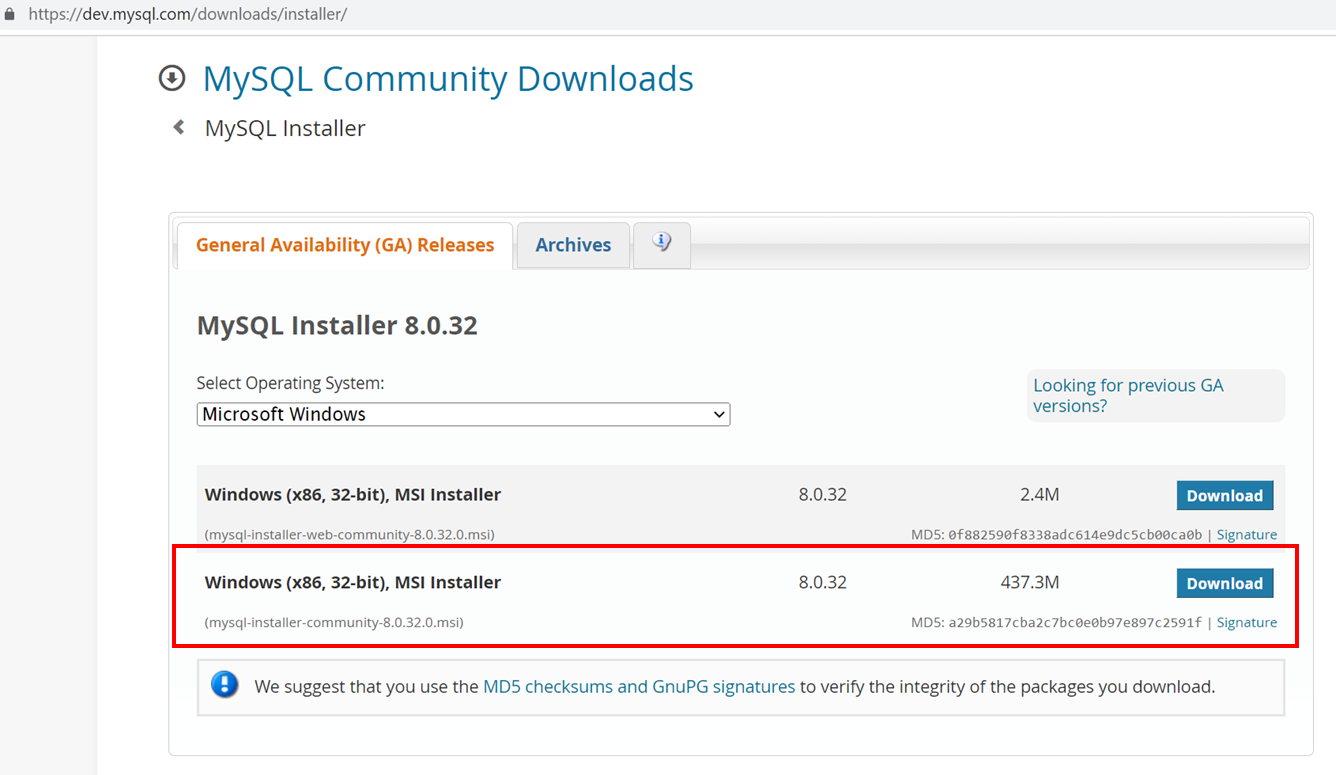
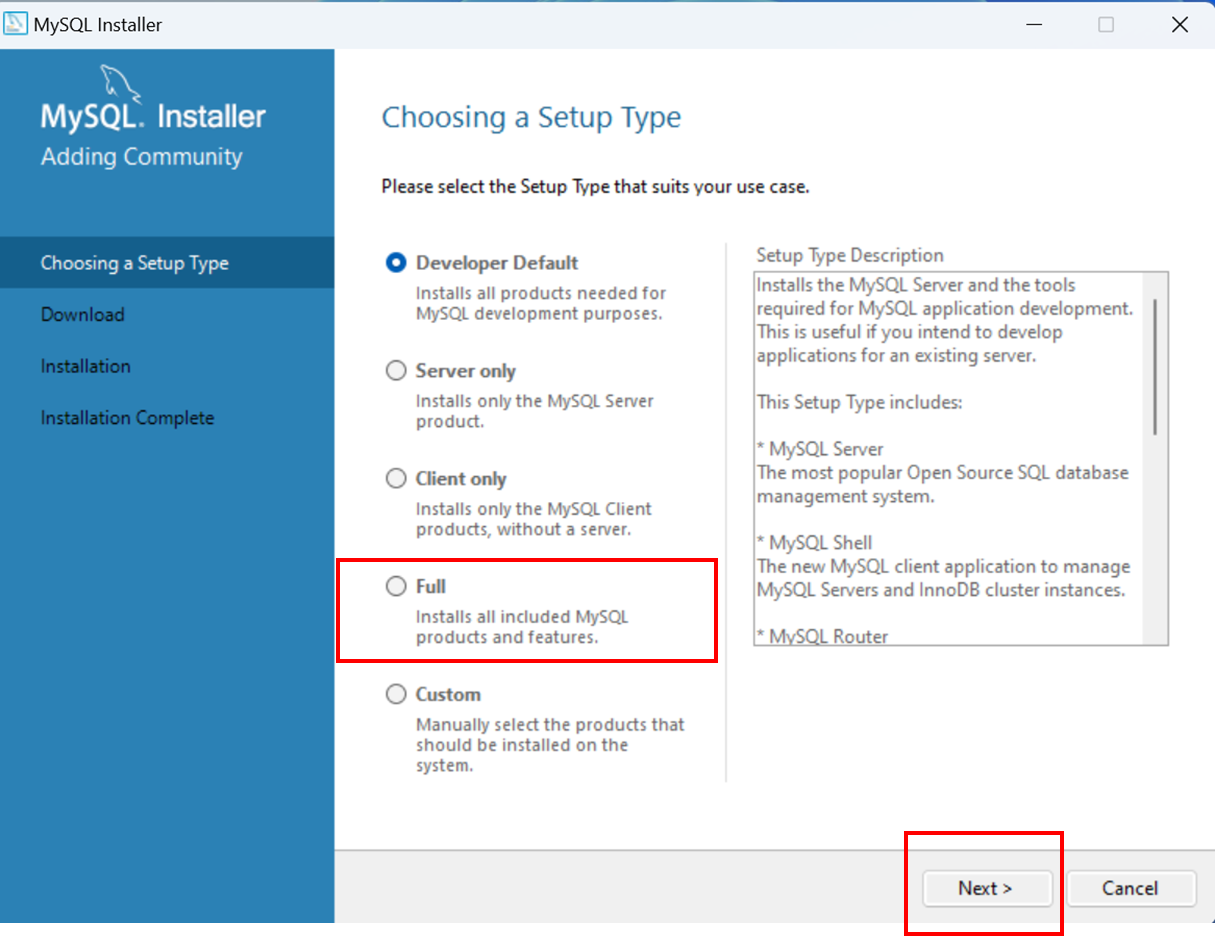
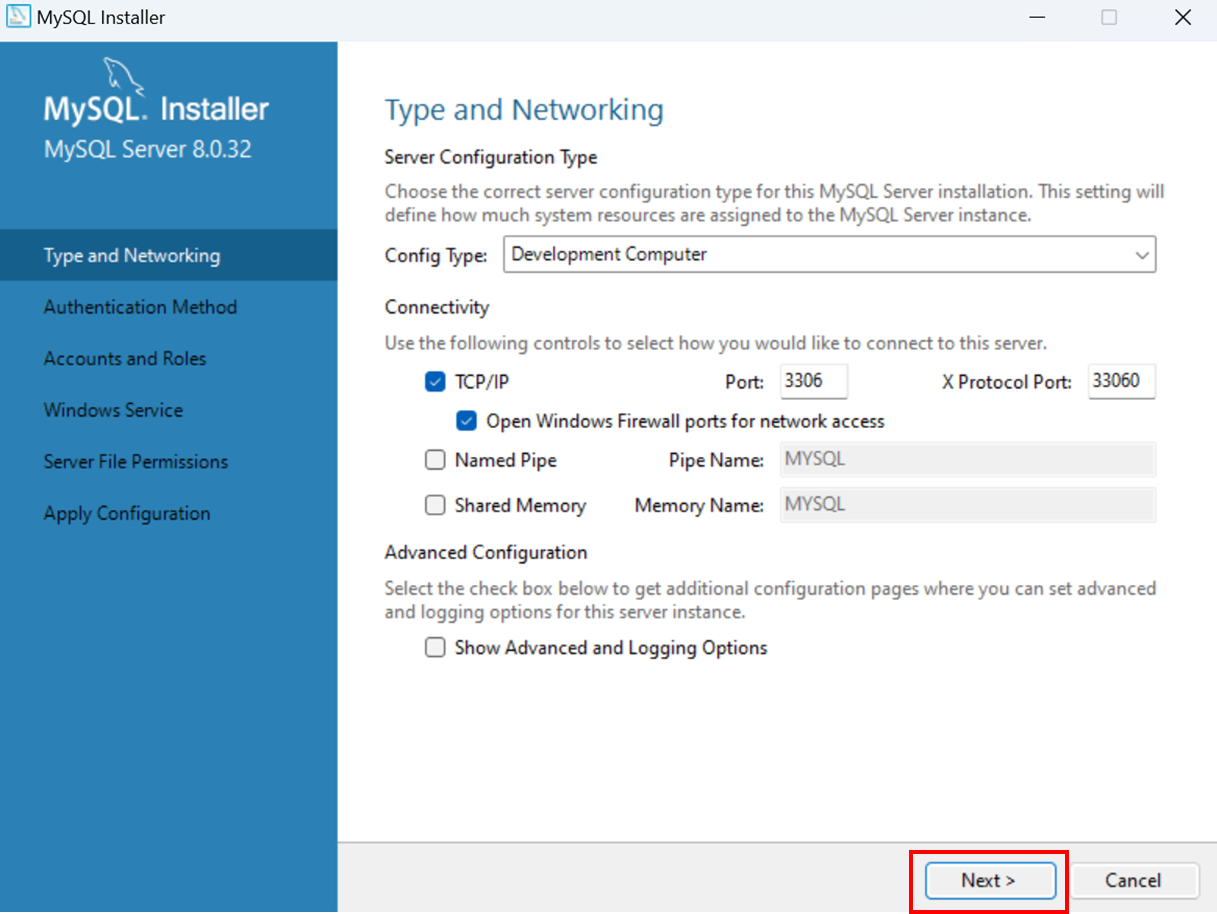
Télécharger la dernière version de MySQL:
https://dev.mysql.com/downloads/installer/
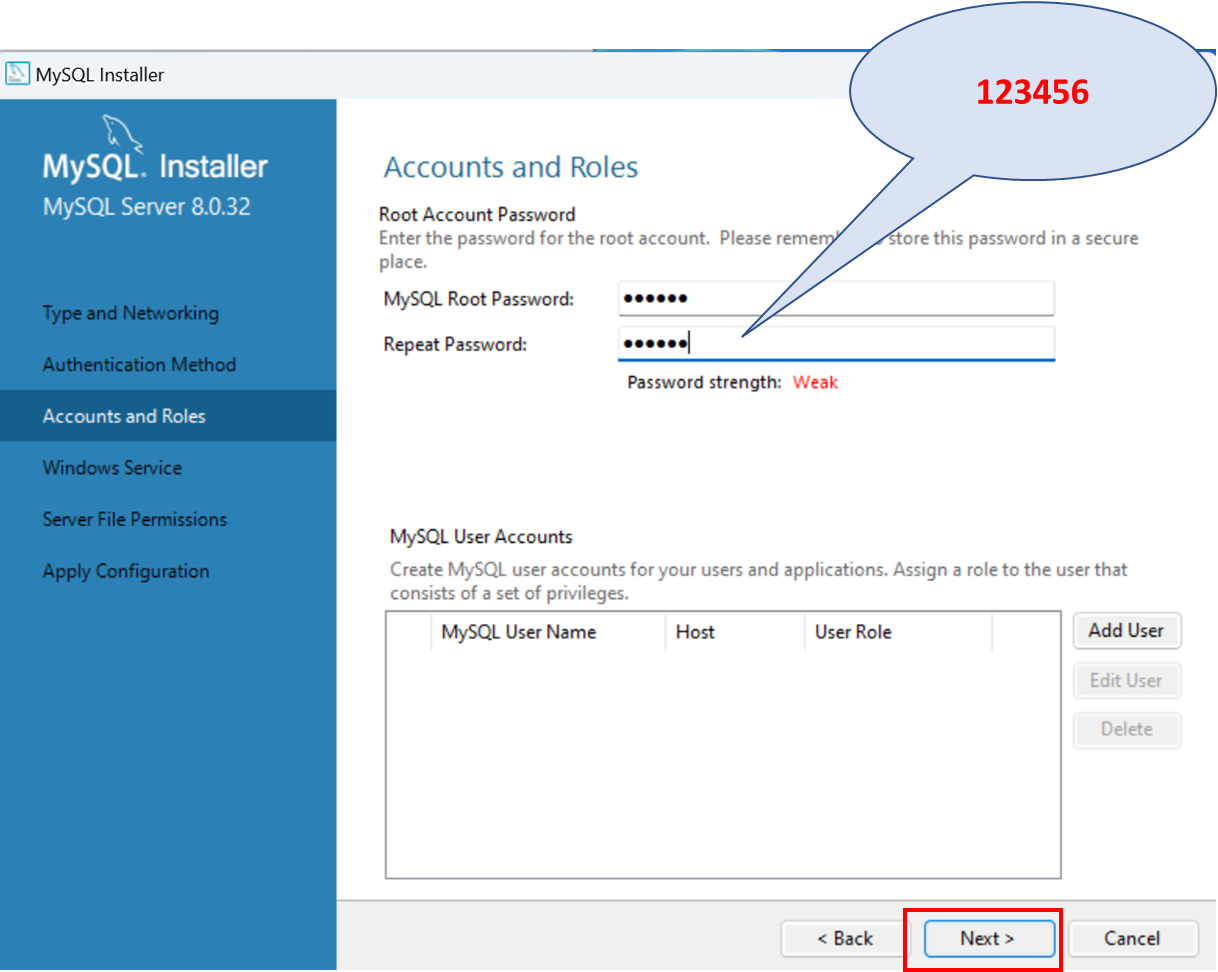
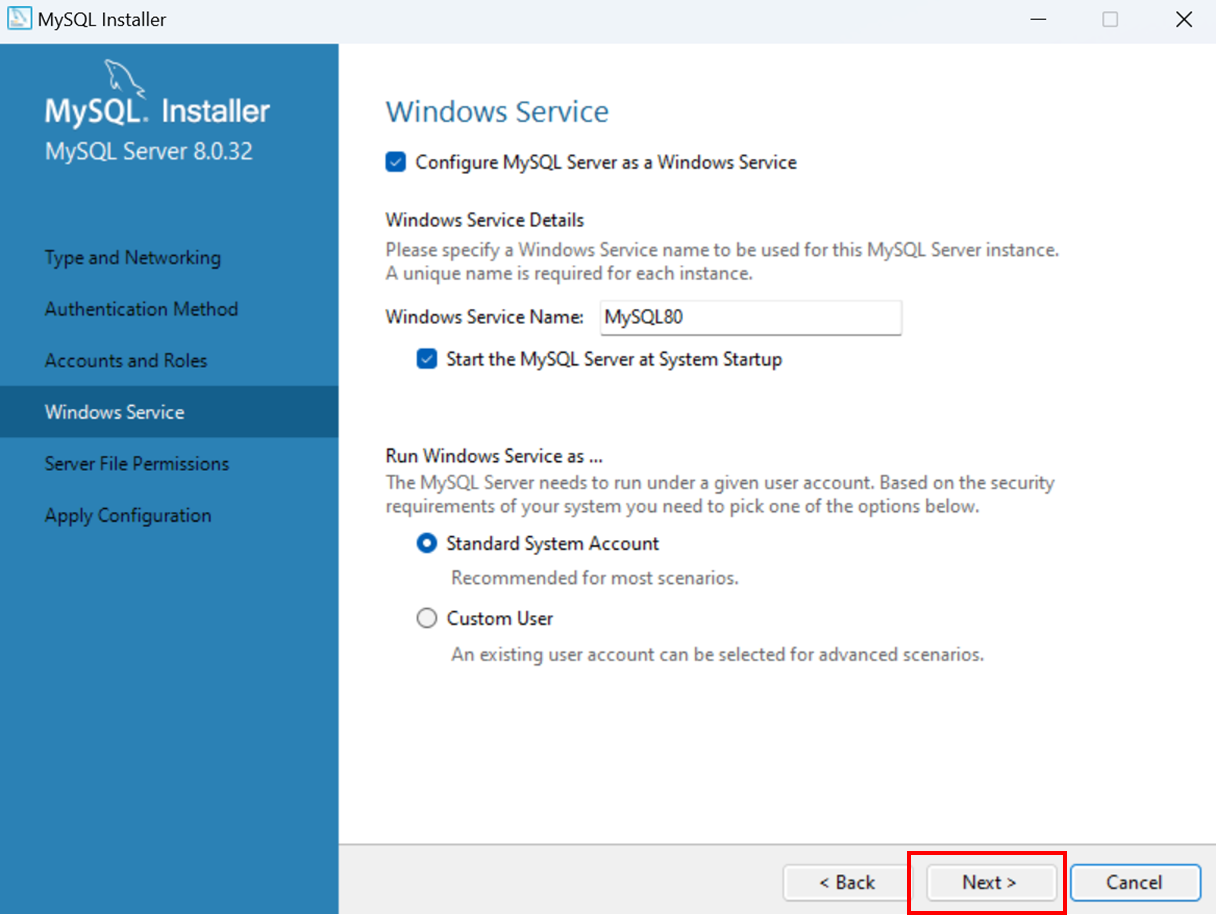
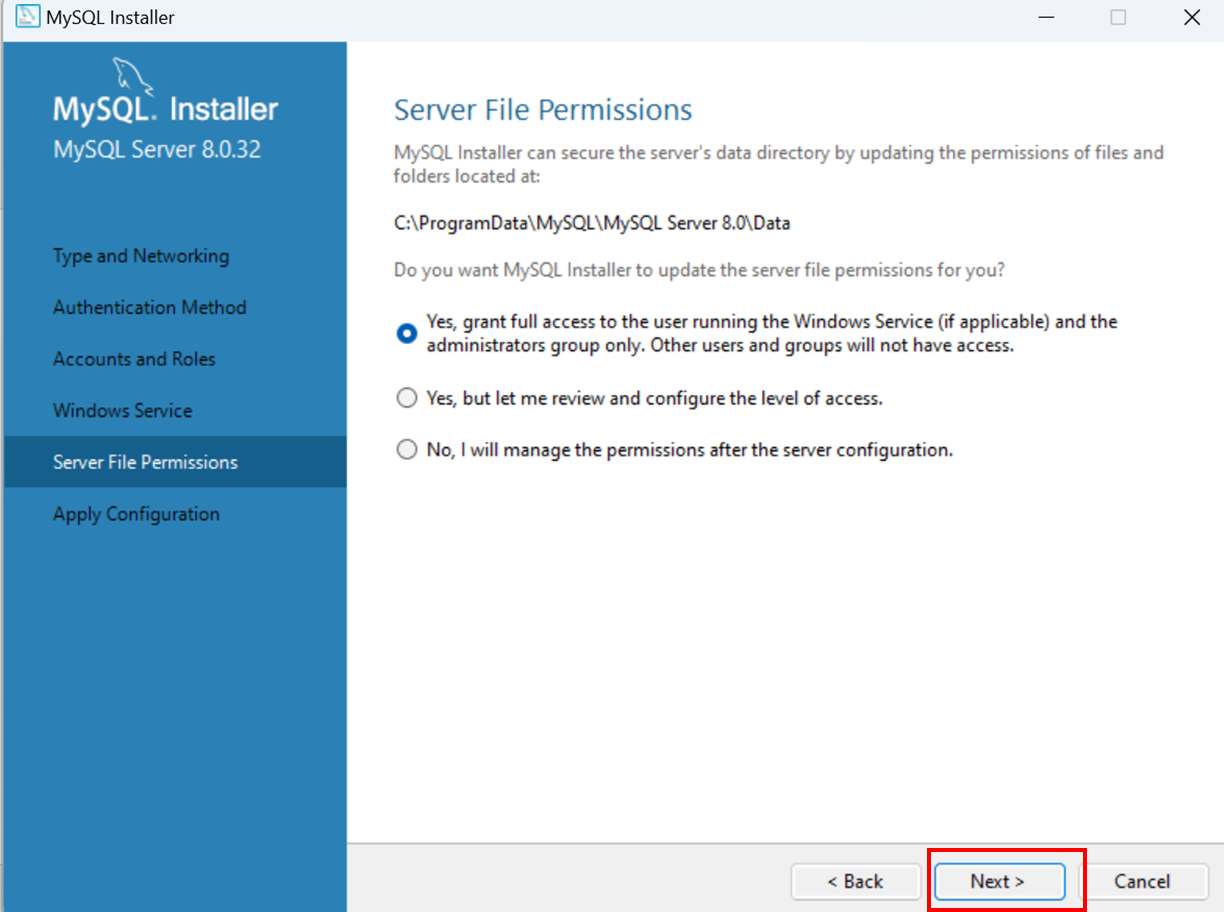
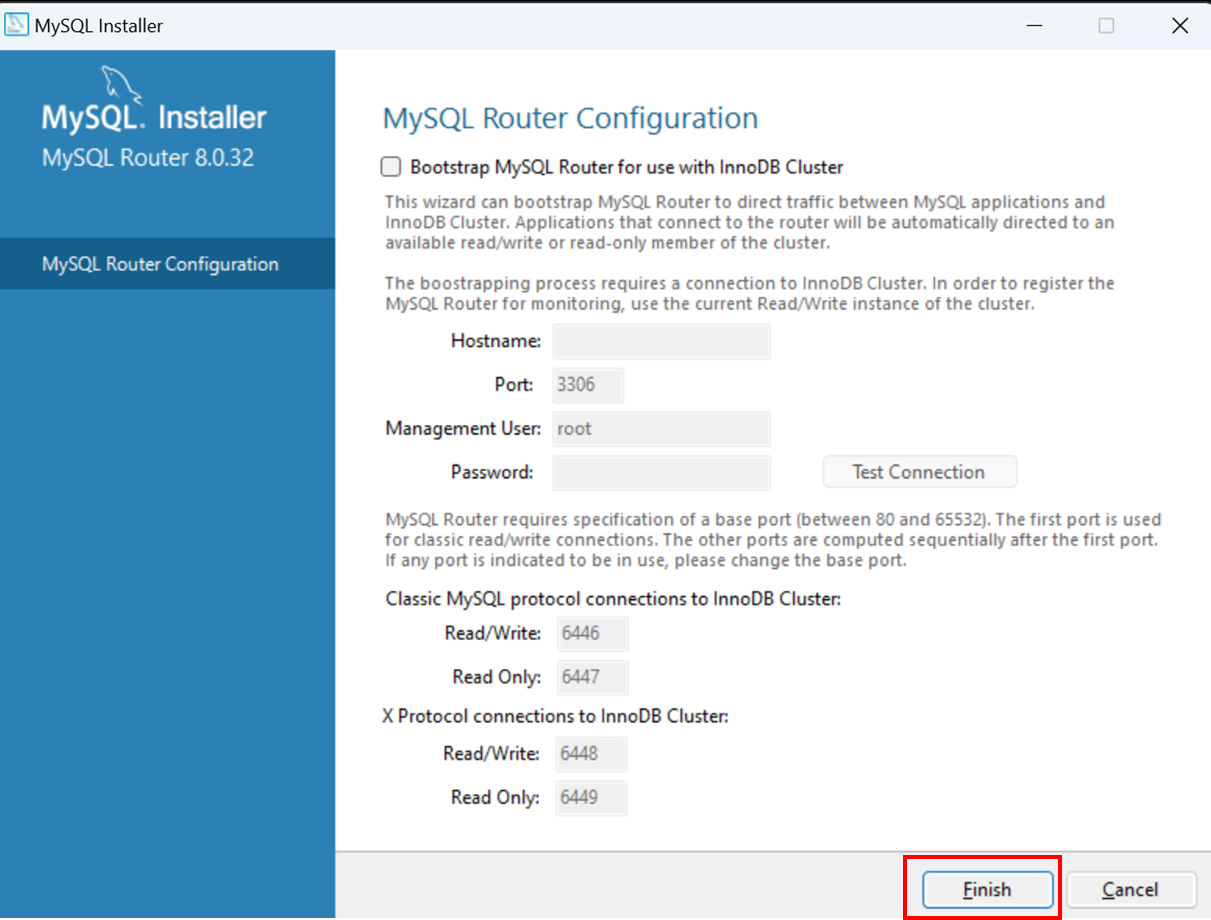
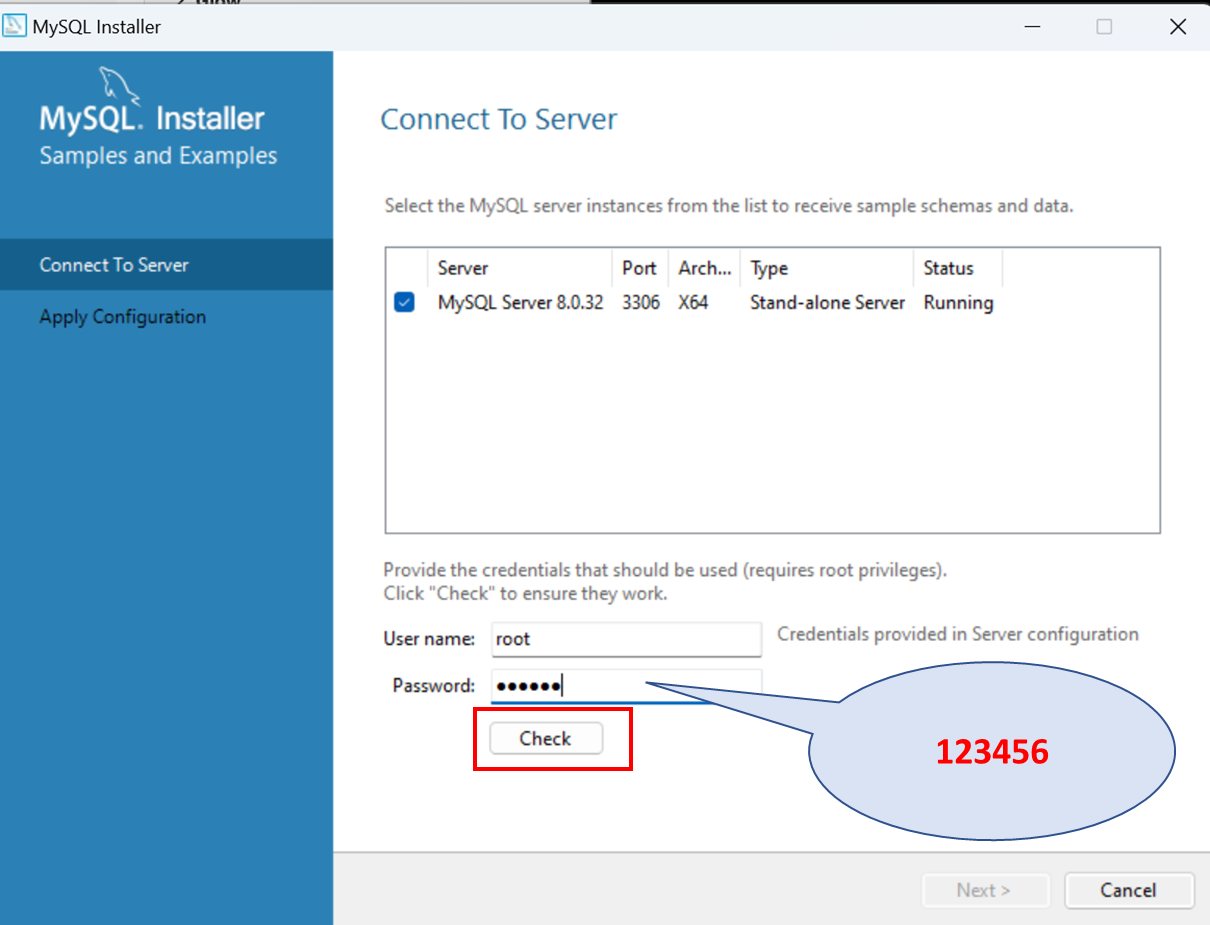
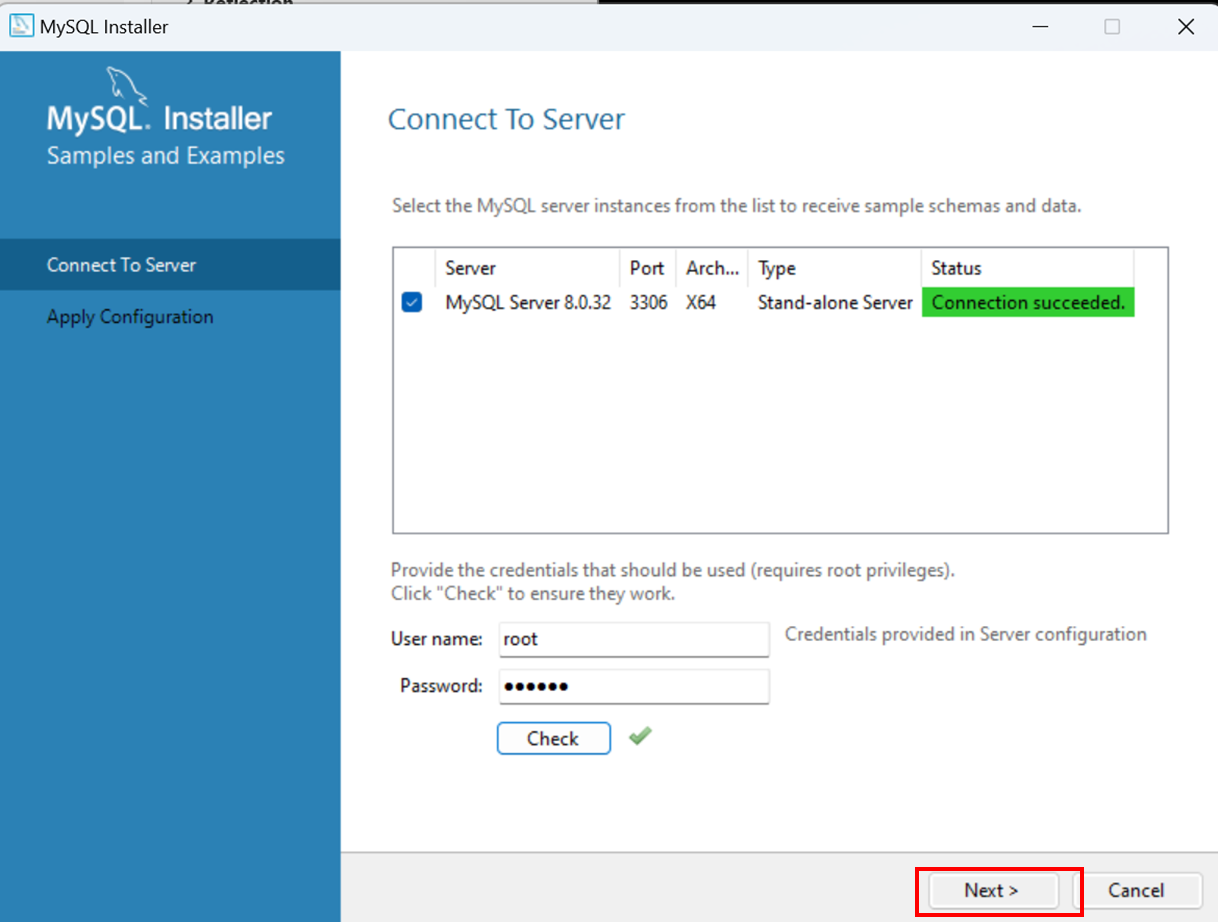
¶ Workbench
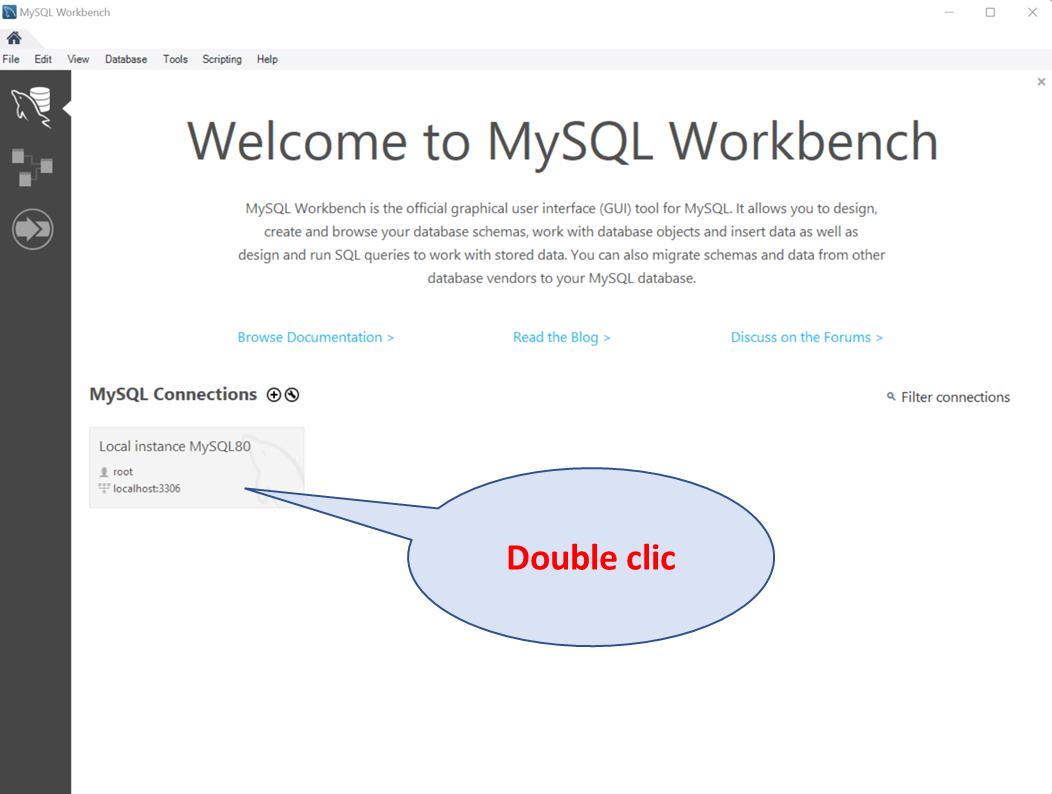
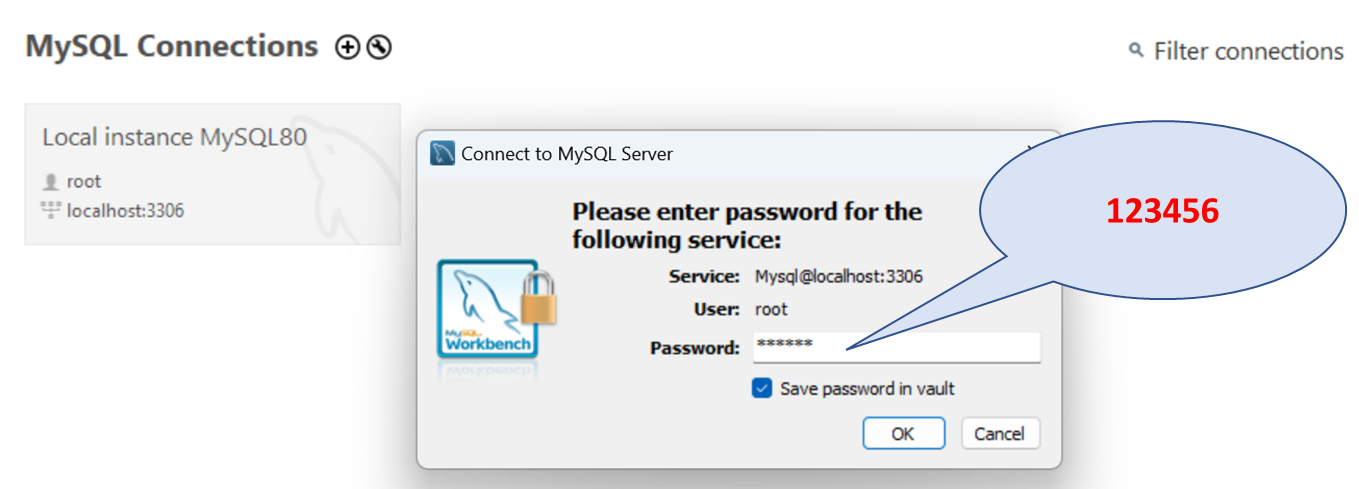
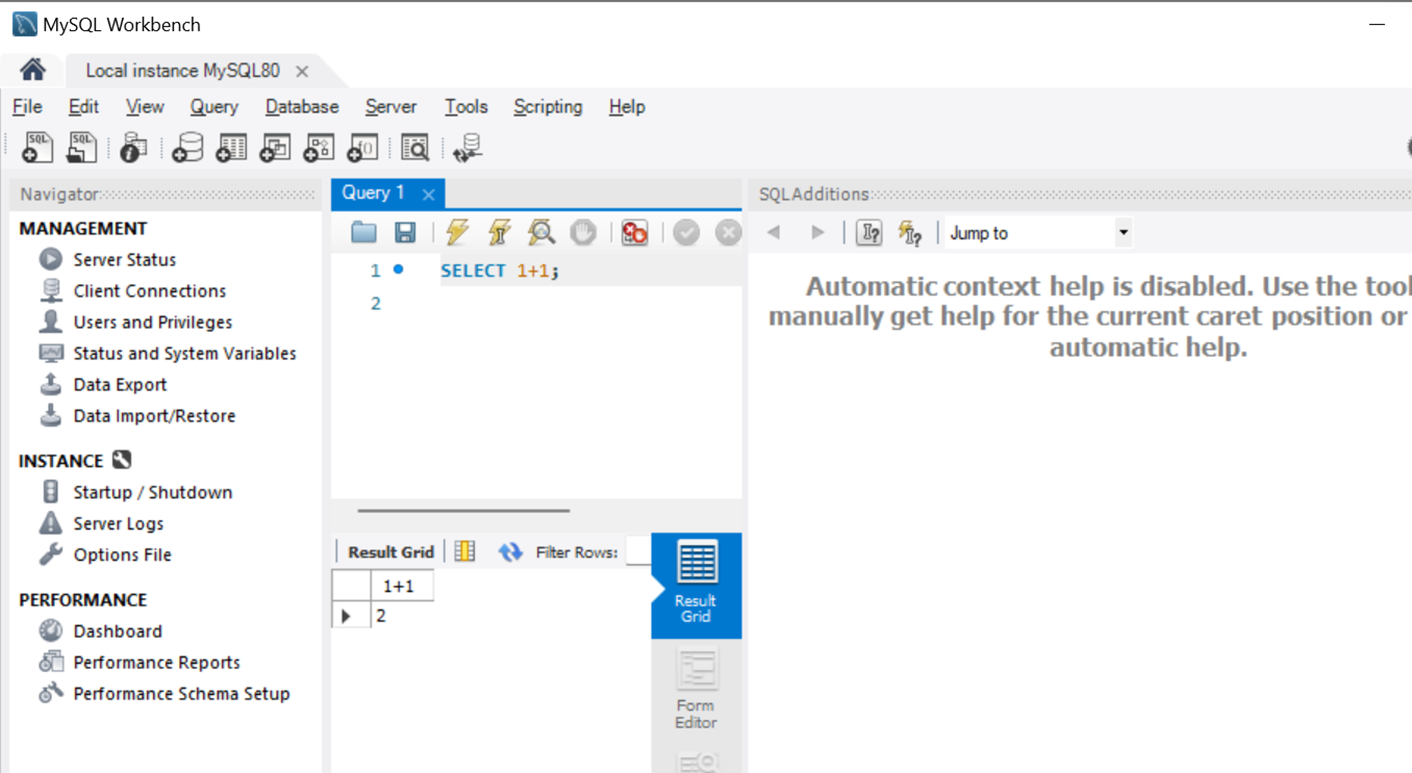
¶ MySQL Command Line
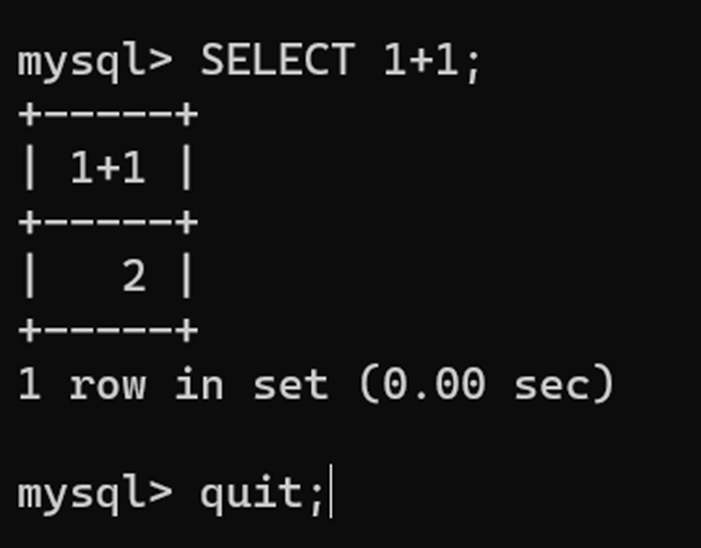
¶ Définition et commandes SQL
¶ Table
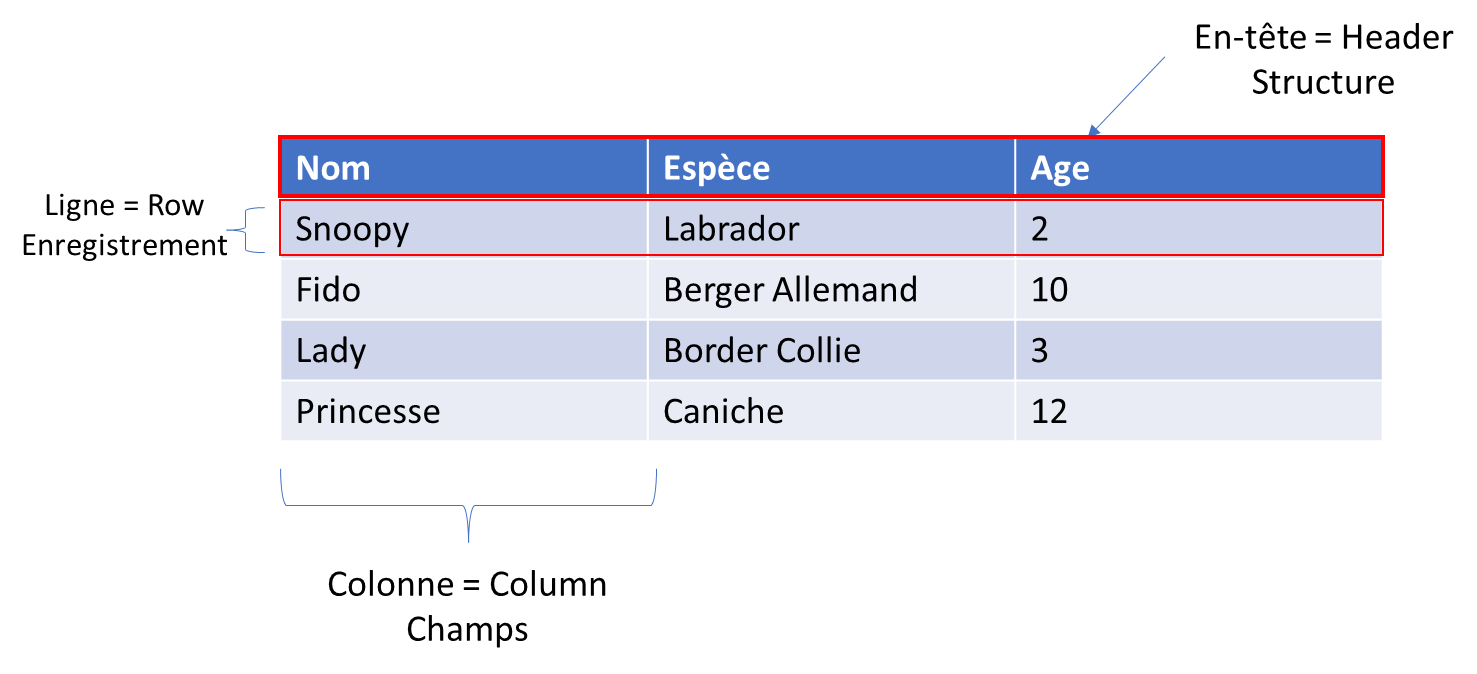
Une table SQL est une structure de données organisée en lignes (enregistrements) et en colonnes (attributs) permettant de stocker des informations de manière structurée dans une base de données.
- Les BD contiennent des tables.
- Les tables contiennent les données.
¶ Définitions
Table : Une structure de données qui stocke des enregistrements dans une base de données.
Enregistrement (ou ligne) : Une entrée individuelle dans une table représentant une instance de données.
Colonne (ou champ/attribut) : Une structure de données qui représente une propriété spécifique dans une table.
Clé primaire : Une colonne ou un ensemble de colonnes qui identifie de manière unique chaque enregistrement dans une table.
Clé étrangère : Une colonne ou un ensemble de colonnes qui référence la clé primaire d'une autre table, établissant ainsi une relation entre les tables.
Index : Une structure de données qui améliore la vitesse de recherche des enregistrements dans une table.
Requête : Une instruction SQL utilisée pour interagir avec une base de données, comme SELECT, INSERT, UPDATE ou DELETE.
Base de données relationnelle : Un type de base de données qui organise les données en tables reliées les unes aux autres par des clés.
SQL (Structured Query Language) : Un langage de programmation utilisé pour gérer et interroger des bases de données relationnelles.
Normalisation : Le processus de conception de bases de données visant à réduire la redondance et à améliorer l'intégrité des données.
Dénormalisation : Le processus de simplification d'une base de données en introduisant délibérément de la redondance pour améliorer les performances.
Transaction : Un ensemble d'instructions SQL formant une unité logique de travail, souvent exécuté de manière atomique (tout ou rien).
Vue : Une représentation virtuelle d'une ou plusieurs tables dans une base de données, créée à partir d'une requête.
Procédure stockée : Un ensemble d'instructions SQL précompilées qui peuvent être exécutées en tant qu'unité dans une base de données.
Trigger (déclencheur) : Un ensemble d'instructions associées à une table qui est automatiquement activé en réponse à certaines opérations sur la table (INSERT, UPDATE, DELETE).
Schéma : La structure organisationnelle globale d'une base de données, définissant les tables, les relations et d'autres objets.
Cluster : Un groupe de serveurs de base de données travaillant ensemble pour fournir une haute disponibilité ou une meilleure performance.
Jalonnement (Locking) : La méthode de contrôle de l'accès concurrentiel aux données pour éviter les conflits.
¶ Commandes SQL
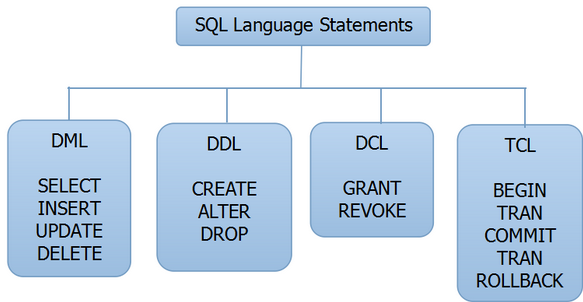
En SQL, il y a 4 types de commandes:
DDL (Data Definition Language) : Les commandes DDL sont utilisées pour créer, modifier et supprimer des objets dans une base de données. Les commandes DDL sont utilisées pour créer des tables, des vues, des index, des procédures stockées, des fonctions et des déclencheurs. Les commandes DDL incluent CREATE, ALTER et DROP.
- CREATE : créer une table, base de données, vue, index
- ALTER : modifier la structure d'une table
- DROP : supprimer une table, base de données
- TRUNCATE : vider une table
- RENAME : renommer un objet
DML (Data Manipulation Language) : Les commandes DML sont utilisées pour manipuler les données à l'intérieur de la base de données. Les commandes DML sont utilisées pour insérer, mettre à jour et supprimer des données dans une table. Les commandes DML incluent INSERT, UPDATE et DELETE.
- SELECT : récupérer des données
- INSERT : ajouter des données
- UPDATE : modifier des données existantes
- DELETE : supprimer des données
DCL (Data Control Language) : Les commandes DCL sont utilisées pour définir les droits d'accès des utilisateurs à la base de données. Les commandes DCL incluent GRANT et REVOKE.
- GRANT : donner des permissions
- REVOKE : retirer des permissions
TCL (Transaction Control Language) : Les commandes TCL sont utilisées pour gérer les transactions dans une base de données. Les commandes TCL incluent COMMIT, ROLLBACK et SAVEPOINT.
- COMMIT : valider une transaction
- ROLLBACK : annuler une transaction
- SAVEPOINT : créer un point de sauvegarde
- SET TRANSACTION : définir les caractéristiques d'une transaction
¶ Commandes de type DDL
- CREATE DATABASE : Crée une nouvelle base de données.
- DROP DATABASE : Supprime une base de données existante.
- USE : Sélectionne la base de données à utiliser.
- CREATE TABLE : Crée une nouvelle table dans la base de données.
- ALTER TABLE : Modifie la structure d'une table existante.
- DROP TABLE : Supprime une table existante.
- CREATE INDEX : Crée un index sur une ou plusieurs colonnes de la table.
- DROP INDEX : Supprime un index existant.
- CREATE VIEW : Crée une vue virtuelle basée sur une requête SQL.
- DROP VIEW : Supprime une vue existante.
- TRUNCATE TABLE : Supprime toutes les lignes d'une table sans supprimer la structure.
CREATE DATABASE Pablo;
USE Pablo;
CREATE TABLE pablotable (prenom varchar(10));
DROP TABLE pablotable;
SELECT database();
DROP DATABASE Pablo;¶ Consistance des données
Les données dans un table SQL doivent oujours être consistants.
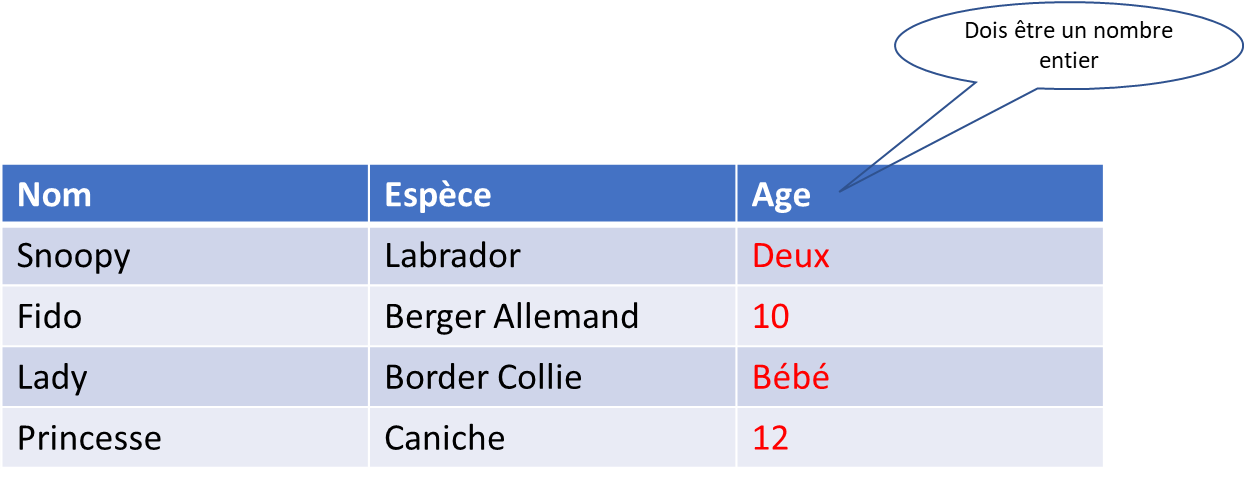
Calculer l’âge d’un chien?
Il faut donc revoir les types de données du tableau précédent et standardiser ceux-ci.
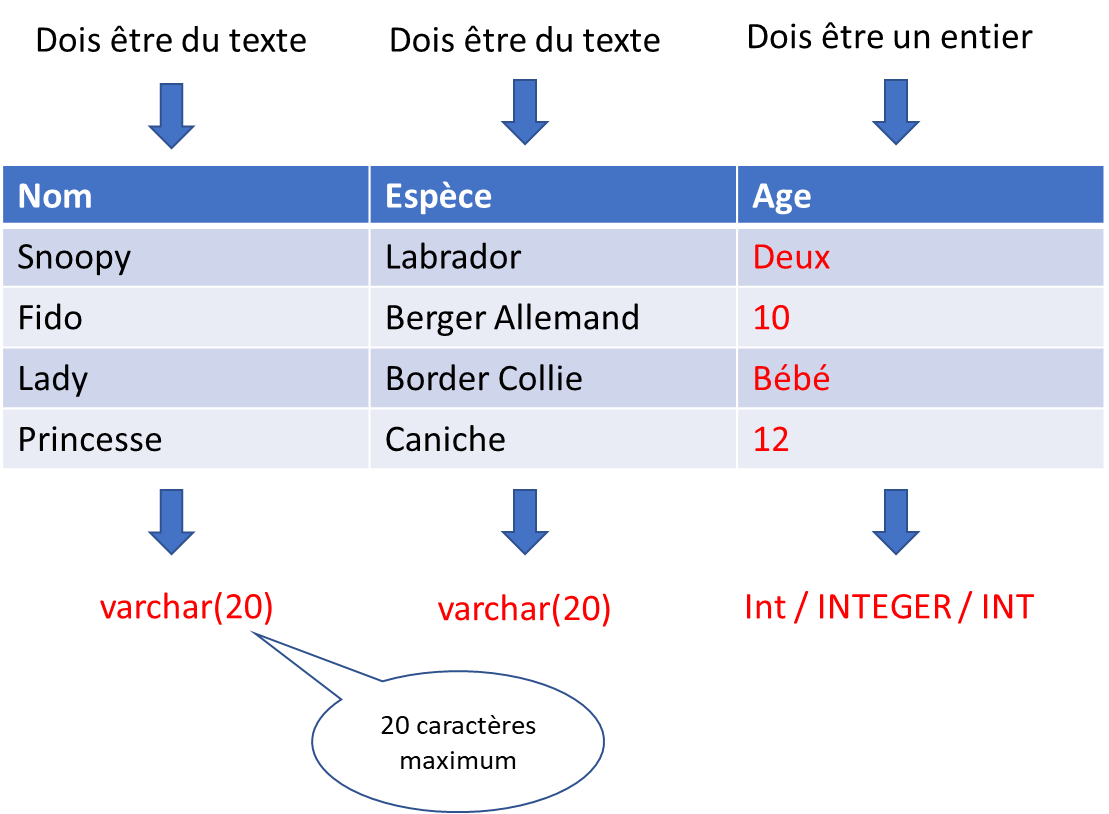
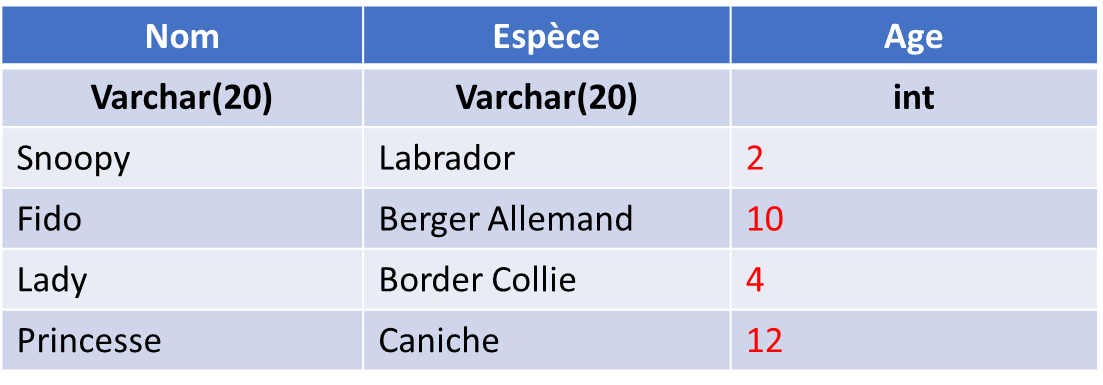
Nous avons alors une table consitante:
¶ Type de données
SQL gère plusierus types de données
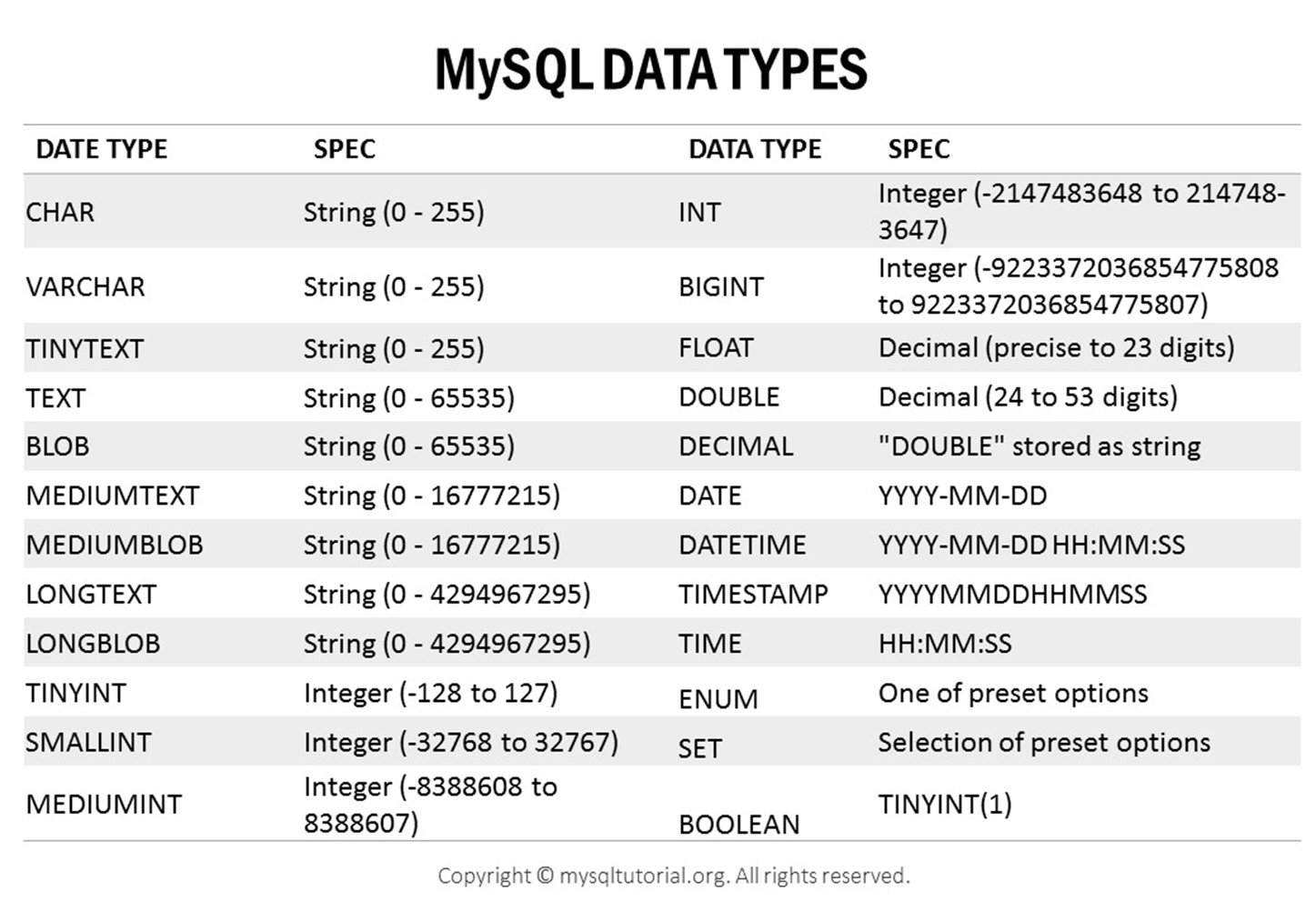
Types Numériques :
- Entiers
- TINYINT (-128 à 127) ou (0 à 255 non signé)
- SMALLINT (-32 768 à 32 767)
- MEDIUMINT (-8388608 à 8388607)
- INT/INTEGER (-2 147 483 648 à 2 147 483 647)
- BIGINT (-9223372036854775808 à 9223372036854775807)
Pour les types numériques, vous pouvez ajouter UNSIGNED pour n'autoriser que les valeurs positives
- Décimaux
- DECIMAL(M,D) ou NUMERIC - nombres exacts
- FLOAT(M,D) - nombres à virgule flottante simple précision
- DOUBLE(M,D) - nombres à virgule flottante double précision
Pour les types décimaux, M représente le nombre total de chiffres et D le nombre de décimales
Types Chaînes de caractères :
- Texte
- CHAR(M) - longueur fixe (max 255)
- VARCHAR(M) - longueur variable (max 65535)
- TINYTEXT (max 255)
- TEXT (max 65535)
- MEDIUMTEXT (max 16777215)
- LONGTEXT (max 4294967295)
La taille maximale des champs VARCHAR dépend de la version de MySQL et de l'encodage utilisé
- Binaire
- BINARY(M) - longueur fixe
- VARBINARY(M) - longueur variable
- TINYBLOB (max 255)
- BLOB (max 65535)
- MEDIUMBLOB (max 16777215)
- LONGBLOB (max 4294967295)
Types Date et Heure :
- DATE - Format 'YYYY-MM-DD'
- TIME - Format 'HH:MM:SS'
- DATETIME - Format 'YYYY-MM-DD HH:MM:SS'
- TIMESTAMP - Format 'YYYY-MM-DD HH:MM:SS'
- YEAR - Format 'YYYY'
TIMESTAMP
Un "timestamp" est un type de données qui stocke une date et une heure précises (horodateur). Il est utilisé pour stocker des informations sur le moment où une entrée de base de données a été créée ou modifiée pour la dernière fois.
Plus précisément, un timestamp stocke le nombre de secondes écoulées depuis le 1er janvier 1970 à 00:00:00 UTC (également appelé "epoch time") jusqu'à la date et l'heure spécifiées. MySQL stocke les timestamp sous forme de nombres entiers à quatre octets, ce qui signifie qu'il peut stocker des dates allant de 1er janvier 1970 à 19 janvier 2038 (la limite de 32 bits pour le stockage de nombres entiers).
Les timestamp sont souvent utilisés pour les fonctions de suivi et de journalisation dans les applications Web, telles que les horodatages des messages de chat, les dates d'inscription des utilisateurs et les horaires de publication des articles de blog.
Il est important de noter que MySQL stocke les timestamp en utilisant le fuseau horaire par défaut du serveur MySQL. Cela peut parfois causer des problèmes si vous travaillez avec des fuseaux horaires différents ou si vous souhaitez afficher des timestamp dans un fuseau horaire différent de celui du serveur MySQL. Dans ce cas, vous devrez prendre en compte la conversion des fuseaux horaires lors de l'utilisation de timestamp dans votre application.
TIMESTAMP prends moins d’espace comparativement à DATETIME mais son intervalle ’range’ est beaucoup plus petit.
Source: : https://dev.mysql.com/doc/refman/8.0/en/datetime.html
Types Spéciaux :
- ENUM - Liste de valeurs possibles
- SET - Ensemble de valeurs possibles
- JSON - Stockage de données JSON
- BOOLEAN/BOOL - Vrai (1) ou Faux (0)
Types Spatiaux :
- GEOMETRY
- POINT
- LINESTRING
- POLYGON
- MULTIPOINT
- MULTILINESTRING
- MULTIPOLYGON
- GEOMETRYCOLLECTION
Pour plus d'info sur les data type: https://dev.mysql.com/doc/refman/8.0/en/data-types.html
¶ Signed vs Unsigned
Un nombre peut être signé (par défaut) ou non signé.
Signed (Signé) :
- Peut contenir des nombres positifs ET négatifs
- Utilise un bit pour stocker le signe (+ ou -)
- La plage est divisée entre nombres positifs et négatifs
Unsigned (Non signé) :
- Ne peut contenir QUE des nombres positifs
- N'utilise pas de bit pour le signe
- Toute la plage est utilisée pour les nombres positifs
-- Signed TINYINT
TINYINT: -128 à +127
-- Unsigned TINYINT
TINYINT UNSIGNED: 0 à 255¶ Les guillemets simple et double
En SQL, les guillemets double (") et les guillemets simples ou apostrophes (') sont utilisés pour délimiter les chaînes de caractères. Cependant, il existe une différence subtile entre les deux :
- L'utilisation des guillemets doubles (" ") est une fonctionnalité propre à certains SGBD, tels que MySQL et SQL Server. Les guillemets doubles peuvent être utilisés pour délimiter des chaînes de caractères, mais seulement si les options SQL_MODE sont configurées pour les autoriser. Les guillemets doubles sont également utilisés pour délimiter les noms de colonnes, de tables ou d'autres objets de base de données contenant des caractères spéciaux ou des espaces.
- L'utilisation de l'apostrophe simple (' ') est la méthode standard pour délimiter les chaînes de caractères en SQL. Les apostrophes simples sont utilisées pour encadrer les valeurs littérales, telles que des chaînes de caractères ou des dates, dans des requêtes SQL. Les apostrophes simples sont également utilisées pour les comparaisons de chaînes de caractères dans les clauses WHERE ou HAVING d'une requête.
INSERT INTO pet_shop.people(first_name) VALUES (‘L\’eau Bleu’)
#Autres exemples: (‘Elle a dit: "Je suis malade"’)¶ Les commentaires
Nous pouvons mettres des commentaires dans nos script. Le symbole --, # ou /* permet de mettre des commentaires. Voici quelques exemples:
-- Ceci est un commentaire sur une ligne
SELECT * FROM users; -- Commentaire en fin de ligne
# Ceci est aussi un commentaire sur une ligne
/* Ceci est un commentaire
sur plusieurs lignes
qui peut continuer ici */
SELECT * FROM users;
/*
* Style structuré
* pour les commentaires
* sur plusieurs lignes
*/
SELECT *
FROM users /* on sélectionne la table users */
WHERE status = 1; /* uniquement les utilisateurs actifs */
- Les commentaires
--doivent être suivis d'un espace - Le style
#est spécifique à MySQL - Les commentaires
/* */peuvent s'étendre sur plusieurs lignes - Tous ces styles peuvent être utilisés dans les scripts SQL et dans la ligne de commande MySQL
¶ Création d'une table
La commande CREATE TABLE en MySQL permet de créer une nouvelle table dans une base de données en définissant son nom, ses colonnes avec leurs types de données respectifs (comme INT, VARCHAR, DATE) et leurs contraintes éventuelles (comme PRIMARY KEY, NOT NULL, FOREIGN KEY).
Soit la création d'une BD ainsi que d'une table selon l'exemple ci-dessous:
# DROP DATABASE pet_shop;
# Ceci est un commentaire
CREATE DATABASE pet_shop;
USE pet_shop;
CREATE TABLE meschiens
(
name VARCHAR(20),
race VARCHAR(20),
age INT
);
# Même code sur 1 ligne
# CREATE TABLE meschiens (name VARCHAR(20),race VARCHAR(20),age INT);Nous pouvons créer cette table de 3 façons différentes:
- À partir de Workbench
- En command line
- À l'aide de l'interface graphique

Comment nous confirmons la création de notre table?
SHOW TABLES;
#SHOW COLUMNS FROM <tablename>
SHOW COLUMNS FROM meschiens;
#DESC <tablename>
DESC meschiens;De manière graphique:
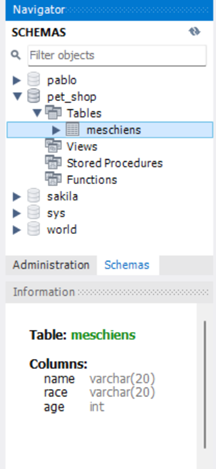
¶ Suppresion d'une table
La commande DROP TABLE est une instruction SQL qui supprime définitivement une table et toutes ses données de la base de données, y compris sa structure, ses index et ses contraintes.
-- Syntaxe 1 : Supprimer simplement une table
DROP TABLE nom_table;
-- Syntaxe 2 : Supprimer une table seulement si elle existe (évite les erreurs)
DROP TABLE IF EXISTS nom_table;
-- Syntaxe 3 : Supprimer plusieurs tables à la fois
DROP TABLE table1, table2, table3;
-- Syntaxe 4 : Supprimer plusieurs tables si elles existent
DROP TABLE IF EXISTS table1, table2, table3;Nous pouvons supprimer une table de 3 façons différentes:
- À partir de Workbench
- En command line
- À l'aide de l'interface graphique

Points importants à noter :
- DROP TABLE supprime définitivement la table et toutes ses données
- Cette opération est irréversible (sauf si vous avez une sauvegarde)
- Il faut avoir les droits appropriés pour supprimer une table
- L'utilisation de IF EXISTS est recommandée pour éviter les erreurs
- Si la table a des relations (clés étrangères) avec d'autres tables, il faudra soit :
- Supprimer d'abord les relations
- Utiliser CASCADE si votre configuration le permet
⚠️ Attention : Toujours faire une sauvegarde avant de supprimer une table en production !
¶ CRUD
¶ Définition
Qu'est-ce que le CRUD?
Le CRUD est un acronyme qui représente les quatre principales opérations de base effectuées sur les données dans un système de gestion de base de données relationnelle tel que SQL. Les opérations CRUD sont :
- Create (Créer) : cette opération permet d'ajouter une nouvelle ligne à une table de base de données. Cela peut être réalisé à l'aide de la commande INSERT qui permet d'insérer des données dans une table.
- Read (Lire) : cette opération permet de récupérer des données à partir d'une table de base de données. Cela peut être réalisé à l'aide de la commande SELECT qui permet de sélectionner des données à partir d'une ou plusieurs tables.
- Update (Mettre à jour) : cette opération permet de modifier les données existantes dans une table de base de données. Cela peut être réalisé à l'aide de la commande UPDATE qui permet de mettre à jour les données d'une table.
- Delete (Supprimer) : cette opération permet de supprimer des données d'une table de base de données. Cela peut être réalisé à l'aide de la commande DELETE qui permet de supprimer des données d'une table.
¶ (C) - INSERT
La commande INSERT dans SQL est utilisée pour insérer une nouvelle ligne dans une table de base de données. La syntaxe générale de la commande est la suivante :
- INSERT INTO nom_de_la_table (colonne1, colonne2, colonne3, ...) VALUES (valeur1, valeur2, valeur3, ...);
-- USE pet_shop
use pet_shop;
-- Création de la table meschiens avec 2 champs: name et age
CREATE TABLE meschiens
(
name VARCHAR(20),
age INT
);
-- INSERT sur 2 lignes
INSERT INTO meschiens (name, age)
VALUE ('Minou', 8);
-- INSERT sur 1 ligne
INSERT INTO meschiens (age, name) VALUE (2, 'Minette');
-- INSERT sur 1 ligne (Attention aux colonnes!)
INSERT INTO meschiens (name, age) VALUE ("Meow", 2);
-- Vérification de mon insertion
SELECT * FROM meschiens;
-- Plusieurs INSERT en même temps
INSERT INTO meschiens (name, age)
VALUES
('Princesse', 3),
('Manon', 6),
('Étoile', 13);
-- Vérification de mes insertions
SELECT * FROM pet_shop.meschiens;
-- Ou encore (si USE a été utilisé préalablement)
SELECT * FROM meschiens; Vérification visuelle de mon insertion:
¶ (R) - SELECT
Le READ correspond aux opérations de lecture dans une base de données, principalement réalisées avec la commande SELECT en SQL.
- SELECT colonne 1, colonne2, … FROM nom_table WHERE conditions;
La commande WHERE en SQL permet de filtrer les données d'une table en fonction de critères spécifiques. Elle est utilisée dans les requêtes SELECT, UPDATE ou DELETE pour limiter les résultats retournés en fonction de conditions spécifiques.
-- Lire toutes les colonnes
SELECT * FROM meschiens;
-- Lire des colonnes spécifiques
SELECT name, age FROM meschiens;
SELECT name FROM meschiens;
-- Lire avec condition WHERE
SELECT * FROM meschiens
WHERE age > 5;
-- Lire avec tri ORDER BY
SELECT * FROM meschiens
ORDER BY age DESC;
-- Lire avec limitation LIMIT
SELECT * FROM meschiens
LIMIT 2;
-- Lire avec filtres complexes
SELECT * FROM meschiens
WHERE age BETWEEN 2 AND 5
AND name LIKE 'M%';
-- Lire avec agrégation
SELECT age, COUNT(*) as nombre
FROM meschiens
GROUP BY age;
-- Lire avec la commande WHERE
SELECT * FROM pet_shop.meschiens WHERE age =8;
SELECT name, age FROM pet_shop.meschiens WHERE age >4;
SELECT * FROM pet_shop.meschiens WHERE name ='mInOu' Attention, SQL n'est pas ‘case sensitive’!!!
¶ ALIAS
Un alias est un nom alternatif donné à une table, une colonne ou une expression dans une requête SQL. Il permet de renommer temporairement un élément afin de faciliter la compréhension de la requête ou de raccourcir la longueur des noms utilisés dans la requête.

SELECT * FROM pet_shop.meschiens;
Select name, age FROM pet_shop.meschiens;
Select name AS Nom, age FROM pet_shop.meschiens;
¶ (U) - UPDATE
La commande UPDATE est utilisée pour mettre à jour les données d'une table existante. Elle permet de modifier une ou plusieurs colonnes d'une ou plusieurs lignes dans une table, en fonction des critères spécifiés dans la clause WHERE. La commande UPDATE va de pair avec la commande SET.
- UPDATE nom_de_la_table SET colonne_1 = valeur_1, colonne_2 = valeur_2, ... WHERE condition;
Dans cette commande, la première ligne spécifie la table à mettre à jour, suivie de la clause SET, qui spécifie les colonnes et les valeurs à modifier. Habituellement, la commande UPDATE est utilisé avec le critère WHERE pour limiter son champ d’action.
UPDATE … SET …WHERE
UPDATE meschiens SET name= 'Lune' WHERE name = 'Étoile' Limit 1;
-- Modifier l'âge de Minou
UPDATE meschiens
SET age = 9
WHERE name = 'Minou';
-- Modifier l'âge de tous les chiens qui ont 2 ans
UPDATE meschiens
SET age = 3
WHERE age = 2;
-- Modifier le nom et l'âge d'un chien
UPDATE meschiens
SET name = 'Minouche',
age = 4
WHERE name = 'Meow';
-- ⚠️ Modifier l'âge de tous les chiens (attention, sans WHERE)
UPDATE meschiens
SET age = age + 1;Attention: Il faut désactiver le safe mode dans workbench et redémarrer Workbech
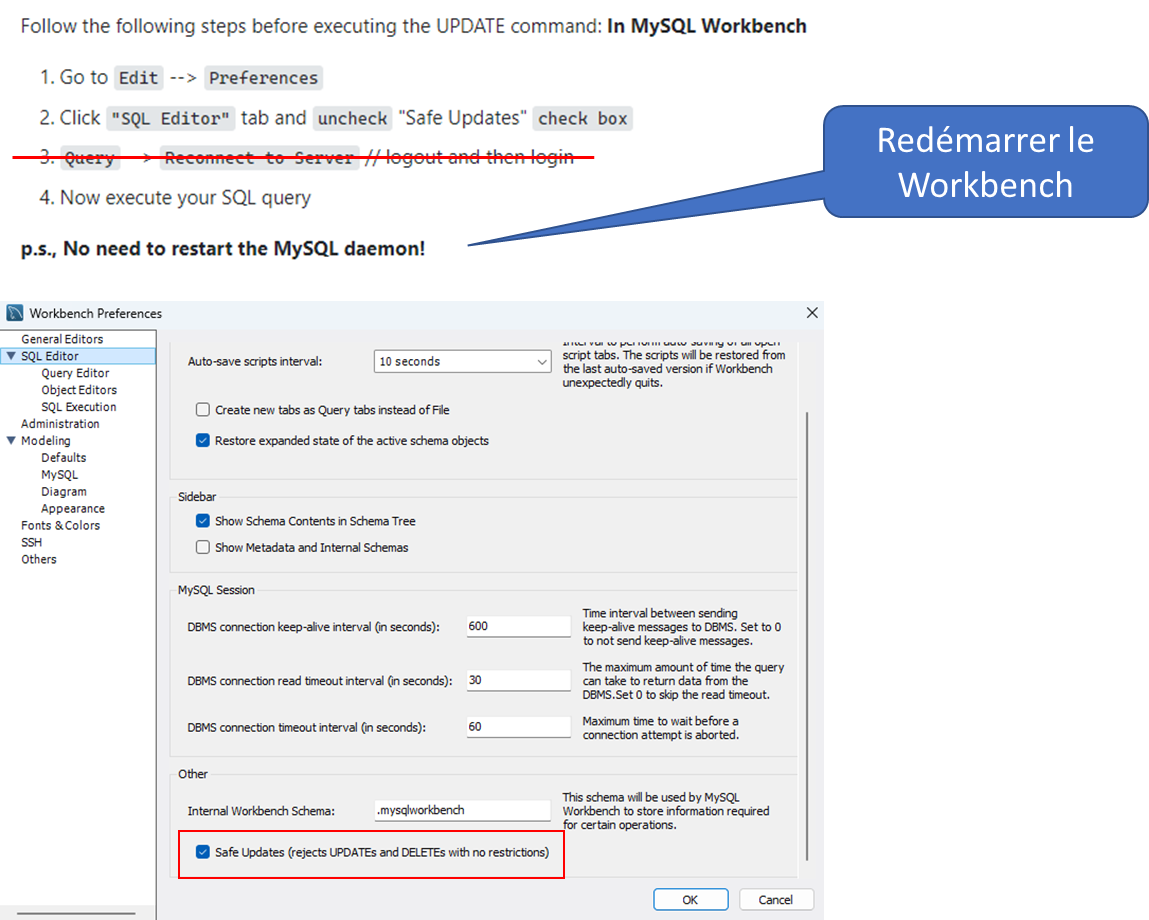
Petit astuce: Avant de faire un UPDATE, faire un SELECT et vérifiez si la condition WHERE donne le bon résultat.
SELECT … FROM… WHERE…
UPDATE…SET…WHERE…
¶ (D) - DELETE
La commande DELETE est utilisée pour supprimer une ou plusieurs lignes d'une table dans une base de données. Elle peut être utilisée pour supprimer des données spécifiques dans une table ou pour supprimer toutes les données d'une table.
- DELETE FROM table_name WHERE condition;
DELETE FROM meschiens WHERE name='Minou';
DELETE FROM meschiens;
DELETE efface le contenu de la table et non la table. Il faut utiliser la commande DROP pour effacer la table.
Petit astuce: Avant de faire un DELETE, faire un SELECT et vérifiez si la condition WHERE donne le bon résultat.
SELECT … FROM… WHERE…
DELETE FROM…WHERE…
¶ Spécificité des champs
¶ NULL (manque de valeur)
En SQL, NULL représente une valeur inconnue ou manquante dans une colonne d'une table. Cela signifie qu'aucune valeur n'a été insérée ou qu'une valeur a été supprimée.
Il est important de comprendre que NULL ne représente pas une chaîne vide, un zéro ou une valeur booléenne false. NULL est une valeur distincte qui indique l'absence de toute valeur valide pour cette colonne (lack of value)
Les fonctions SQL telles que COUNT, SUM et AVG traitent les valeurs NULL différemment des autres valeurs. Par exemple, COUNT(NULL) renvoie 0 plutôt que 1.
Il est important de gérer correctement les valeurs NULL dans les requêtes SQL, car une mauvaise manipulation de ces valeurs peut entraîner des résultats inattendus ou incorrects.

CREATE DATABASE pet_shop;
use pet_shop;
CREATE TABLE people
(
first_name varchar(20) NULL,
last_name varchar(20),
age INT NULL
);
#Insertion enregistrement
INSERT INTO pet_shop.people (first_name,age) VALUES ('Jacques', 19);
#Insertion d'un enregistrement
INSERT into pet_shop.people (first_name) values ('Marc');
SELECT * FROM pet_shop.people;
#Insertion d'un enregistrement vide
INSERT into pet_shop.people () values ();
SELECT * FROM pet_shop.people;
Par défaut, un champs est défini à NULL.
¶ Pourquoi utiliser le NULL
- Données manquantes : Dans certaines situations, les données peuvent ne pas être disponibles ou manquantes pour une colonne spécifique. Dans ce cas, le NULL est utilisé pour représenter l'absence de données.
- Valeurs inconnues : Il peut y avoir des situations où la valeur d'une colonne est inconnue ou incertaine. Dans ce cas, le NULL est utilisé pour représenter cette incertitude.
- Valeurs optionnelles : Dans certains cas, une colonne peut avoir une valeur optionnelle. Dans ce cas, le NULL est utilisé pour indiquer que la colonne peut contenir une valeur ou rester vide.
- Économie d'espace : L'utilisation du NULL peut permettre d'économiser de l'espace de stockage en ne stockant pas de données vides ou inutiles.
¶ NOT NULL
NOT NULL est une contrainte de table qui peut être appliquée à une colonne. Elle indique que la valeur de cette colonne ne peut pas être NULL (c'est-à-dire qu'elle doit toujours contenir une valeur).
Lorsqu'une colonne est définie comme NOT NULL, cela signifie que lors de l'insertion d'une nouvelle ligne dans la table, une valeur doit être spécifiée pour cette colonne. Si une valeur NULL est tentée d'être insérée, une erreur sera générée.
La contrainte NOT NULL garantit que les données contenues dans la colonne sont toujours valides et cohérentes. Elle est donc très utile pour s'assurer de l'intégrité des données stockées dans la table.
NOT NULL garantie une donnée mais ne la valide pas!
CREATE TABLE pet_shop.people2
(
first_name VARCHAR(20) NOT null,
last_name VARCHAR(20) NOT null,
age INT NOT null
);
DESC pet_shop.people2;
#Insertion erronée
INSERT INTO pet_shop.people2 (first_name,age) VALUES ('Jacques', 19);
#Bonne insertion
INSERT INTO pet_shop.people2 (last_name,first_name,age) VALUES ('Jacques','Louis', 19);
# Commandes suivants sont-elles valabes?
INSERT INTO pet_shop.people2 (last_name,first_name,age) VALUES ('19','19','19');
INSERT INTO pet_shop.people2 (last_name,first_name,age) VALUES ('Pablo','The King','19.5');¶ Valeur par défaut
En SQL, une valeur par défaut est une valeur assignée à une colonne lorsqu'aucune valeur explicite n'est spécifiée pour cette colonne lors de l'insertion d'une nouvelle ligne dans une table.
La valeur par défaut peut être utilisée pour éviter les erreurs lors de l'insertion de données dans une table. Si une colonne est définie avec une valeur par défaut et que cette colonne est omise lors de l'insertion, la valeur par défaut sera automatiquement attribuée à la colonne.
CREATE TABLE pet_shop.people3
(
first_name VARCHAR(20) NOT null DEFAULT 'Patrick',
last_name VARCHAR(20) NOT null DEFAULT 'Roy',
age INT NOT null DEFAULT 33
);
INSERT INTO pet_shop.people3 (first_name) VALUES ('Jonathan');
INSERT INTO pet_shop.people3 () VALUES ();
SELECT * FROM pet_shop.people3;
DESC pet_shop.people3;¶ Clé unique
Dans SQL, une clé unique (key) est utilisée pour identifier de manière unique chaque enregistrement dans une table. Une clé unique garantit qu'aucune valeur en double ne peut être stockée dans la colonne de la clé unique, ce qui rend les données de la table plus précises et cohérentes.
Il est important d'avoir une clé unique dans une table car elle permet de:
- Rechercher rapidement des enregistrements spécifiques,
- D'associer des enregistrements dans des tables liées,
- Garantir l'intégrité des données.
Si une table ne possède pas de clé unique, il peut être difficile de rechercher et de mettre à jour des enregistrements spécifiques, et cela peut également conduire à des erreurs lors de la liaison des tables.
Il est important de noter qu'une clé unique peut être composée de plusieurs colonnes. Cette clé est appelée clé primaire (primary key). Les colonnes qui composent la clé primaire doivent être des valeurs uniques et non nulles.
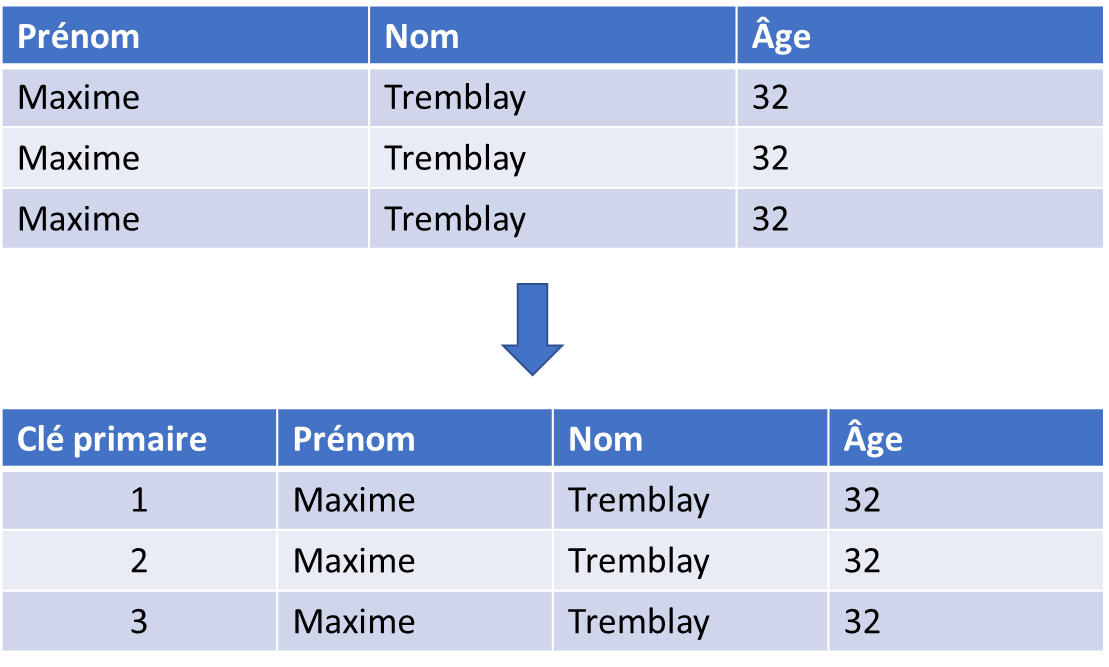
CREATE TABLE pet_shop.people3a
(
people_id INT NOT NULL,
first_name VARCHAR(20) NOT null DEFAULT 'Patrick',
last_name VARCHAR(20) NOT null DEFAULT 'Roy',
age INT NOT null DEFAULT 33
);
-- Insertion de données de test
INSERT INTO pet_shop.people3a (people_id, first_name, last_name, age) VALUES
(1, 'Maxime', 'Tremblay', 32);
-- Erreur, il faut un people_id
INSERT INTO pet_shop.people3a (first_name, last_name, age) VALUES
('Maxime', 'Tremblay', 32);
-- Fonctionne avec un people_id
INSERT INTO pet_shop.people3a (people_id, first_name, last_name, age) VALUES
(2, 'Maxime', 'Tremblay', 32);
-- Qu'est-ce qui arrive si nous écrasons une donnée?
INSERT INTO pet_shop.people3a (people_id, first_name, last_name, age) VALUES
(2, 'Maxime', 'Tremblay', 32);¶ Clé primaire (Primary key)
Une clé primaire (PRIMARY KEY) est un champ ou un ensemble de champs qui identifie de manière unique chaque enregistrement dans une table MySQL, et ne peut contenir de valeur NULL.
¶ Clé étrangère (foreign key)
Une clé étrangère (FOREIGN KEY) est une colonne qui établit une relation entre deux tables en faisant référence à la clé primaire d'une autre table pour maintenir l'intégrité référentielle des données.
¶ Autres types de clé
Unique Key (Clé Unique)
- Similaire à la clé primaire mais peut accepter des valeurs NULL
- Garantit que toutes les valeurs de la colonne sont uniques
- Une table peut avoir plusieurs clés uniques
Composite Key (Clé Composite)
- Une clé composée de plusieurs colonnes
- Peut être une clé primaire ou une clé unique
- L'unicité est basée sur la combinaison des colonnes
Super Key (Super Clé)
- Ensemble d'une ou plusieurs colonnes qui identifient de manière unique un enregistrement
- Peut contenir des attributs supplémentaires non nécessaires à l'unicité
Candidate Key (Clé Candidate)
- Colonne(s) qui pourrai(en)t servir de clé primaire
- Doit être unique et non nulle
- La clé primaire est choisie parmi les clés candidates
Natural Key (Clé Naturelle)
- Une clé basée sur des données réelles existantes
- Par exemple, un numéro de sécurité sociale
- Opposée à une clé artificielle comme un ID auto-incrémenté
Surrogate Key (Clé de Substitution)
- Une clé artificielle créée uniquement pour identifier les enregistrements
- Généralement un ID auto-incrémenté
- N'a pas de signification métier
CREATE TABLE employes (
id INT AUTO_INCREMENT, -- Surrogate Key et Primary Key
num_secu VARCHAR(15) UNIQUE, -- Natural Key et Unique Key
email VARCHAR(100) UNIQUE, -- Unique Key
departement_id INT, -- Foreign Key
PRIMARY KEY (id),
FOREIGN KEY (departement_id) REFERENCES departements(id)
);
CREATE TABLE projets_employes (
employe_id INT,
projet_id INT,
-- Composite Key
PRIMARY KEY (employe_id, projet_id)
);Pour revenir à notre exemple avec une clé primaire:
CREATE TABLE pet_shop.people4
(
people_id INT NOT NULL PRIMARY KEY,
first_name VARCHAR(20) NOT null DEFAULT 'Patrick',
last_name VARCHAR(20) NOT null DEFAULT 'Roy',
age INT NOT null DEFAULT 33
);
CREATE TABLE pet_shop.people4
(
people_id INT NOT NULL,
first_name VARCHAR(20) NOT null DEFAULT 'Patrick',
last_name VARCHAR(20) NOT null DEFAULT 'Roy',
age INT NOT null DEFAULT 33,
PRIMARY KEY (people_id)
);
DESC pet_shop.people4;
INSERT INTO pet_shop.people4 (people_id, first_name, age) VALUES (1,'Maxime', 99);
#Erreur si nous essayons d'écraser un clé qui existe déjà
INSERT INTO pet_shop.people4 (people_id, first_name, age) VALUES (1,'Pablo', 39);
#Clé à 100?
INSERT INTO pet_shop.people4 (people_id, first_name, age) VALUES (101,'Maxime', 99);
#Clé à -100?
INSERT INTO pet_shop.people4 (people_id, first_name, age) VALUES (-100,'Maxime', 99);
#Sans Clé?
INSERT INTO pet_shop.people4 (first_name, age) VALUES ('Maxime', 99);

Question:
- Qu’est-ce qui arrive si nous essayons d’écraser la clé primaire?
- Est-il possible de sauter l’incrément de la clé primaire est allé @ + 999 ou -999?
- Est-ce redondant de mettre NOT NULL à la clé primaire?
MySQL ajoute automatiquement la contrainte NOT NULL à une colonne définie comme PRIMARY KEY.
-- Version explicite
CREATE TABLE utilisateurs (
id INT NOT NULL PRIMARY KEY,
nom VARCHAR(50)
);
-- Version implicite
CREATE TABLE utilisateurs (
id INT PRIMARY KEY, -- NOT NULL est automatiquement ajouté
nom VARCHAR(50)
);¶ Auto-Incrément
La fonction AUTO_INCREMENT permet d’ajouter automatiquement une valeur numérique unique à une colonne chaque fois qu'une nouvelle ligne est insérée dans une table. Cette colonne est souvent utilisée comme clé primaire pour identifier de manière unique chaque ligne dans la table.
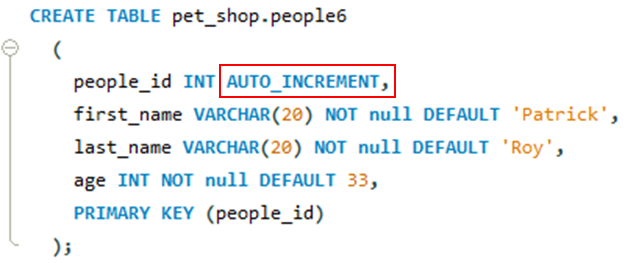
CREATE TABLE pet_shop.people6
(
people_id INT AUTO_INCREMENT,
first_name VARCHAR(20) NOT null DEFAULT 'Patrick',
last_name VARCHAR(20) NOT null DEFAULT 'Roy',
age INT NOT null DEFAULT 33,
PRIMARY KEY (people_id)
);
INSERT INTO pet_shop.people6 (first_name, age) VALUES ('Jonathan', 99);
#Clé 100
INSERT INTO pet_shop.people6 (people_id, first_name, age) VALUES (100,'Jonathan', 99);
#Insertion sans clé, c'est quoi la prochaine valeur de clé?
INSERT INTO pet_shop.people6 (first_name, age) VALUES ('Jonathan', 99);
#Insertion clé à -100?
INSERT INTO pet_shop.people6 (people_id, first_name, age) VALUES (-100,'Jonathan', 99);
#Insertion sans clé, c'est quoi la prochaine valeur de clé?
INSERT INTO pet_shop.people6 (first_name, age) VALUES ('Jonathan', 99);
#Insertion clé à -50?
INSERT INTO pet_shop.people6 (people_id, first_name, age) VALUES (-50,'Jonathan', 99);
#Insertion sans clé, c'est quoi la prochaine valeur de clé?
INSERT INTO pet_shop.people6 (first_name, age) VALUES ('Jonathan', 99);Questions:
- Est-ce que l’insertion sans spécifier le champs ‘people_id’ fonctionne?
- Qu’arrive-t-il si j’exécute la commande INSERT 6 fois de suite?
- Quelle est la description de la table? Quelle est son contenu?
- Est-ce que je peux écraser le champs ‘people_id’?
¶ Raffiner une recherche
¶ Script
Create database Meslivres;
use Meslivres;
CREATE TABLE books
(
book_id INT AUTO_INCREMENT,
title VARCHAR(100),
author_fname VARCHAR(100),
author_lname VARCHAR(100),
released_year INT,
stock_quantity INT,
pages INT,
PRIMARY KEY(book_id)
);
INSERT INTO books (title, author_fname, author_lname, released_year, stock_quantity, pages)
VALUES
('The Namesake', 'Jhumpa', 'Lahiri', 2003, 32, 291),
('Norse Mythology', 'Neil', 'Gaiman',2016, 43, 304),
('American Gods', 'Neil', 'Gaiman', 2001, 12, 465),
('Interpreter of Maladies', 'Jhumpa', 'Lahiri', 1996, 97, 198),
('A Hologram for the King: A Novel', 'Dave', 'Eggers', 2012, 154, 352),
('The Circle', 'Dave', 'Eggers', 2013, 26, 504),
('The Amazing Adventures of Kavalier & Clay', 'Michael', 'Chabon', 2000, 68, 634),
('Just Kids', 'Patti', 'Smith', 2010, 55, 304),
('A Heartbreaking Work of Staggering Genius', 'Dave', 'Eggers', 2001, 104, 437),
('Coraline', 'Neil', 'Gaiman', 2003, 100, 208),
('What We Talk About When We Talk About Love: Stories', 'Raymond', 'Carver', 1981, 23, 176),
("Where I'm Calling From: Selected Stories", 'Raymond', 'Carver', 1989, 12, 526),
('White Noise', 'Don', 'DeLillo', 1985, 49, 320),
('Cannery Row', 'John', 'Steinbeck', 1945, 95, 181),
('Oblivion: Stories', 'David', 'Foster Wallace', 2004, 172, 329),
('Consider the Lobster', 'David', 'Foster Wallace', 2005, 92, 343),
('10% Happier', 'Dan', 'Harris', 2014, 29, 256),
('fake_book', 'Freida', 'Harris', 2001, 287, 428),
('Lincoln In The Bardo', 'George', 'Saunders', 2017, 1000, 367);
##################################
# Distinct
##################################
SELECT author_lname FROM MesLivres.books;
SELECT DISTINCT author_lname FROM MesLivres.books;
#Exercice Question: Comment je fais pour avoir
SELECT author_fname, author_lname FROM MesLivres.books;
SELECT DISTINCT author_fname, author_lname FROM MesLivres.books;
##################################
# WHERE
##################################
-- Livres publiés après 2000
SELECT title, released_year
FROM books
WHERE released_year > 2000;
-- Livres de Neil Gaiman
SELECT title, author_fname, author_lname
FROM books
WHERE author_fname = 'Neil';
-- Livres ayant plus de 300 pages
SELECT title, pages
FROM books
WHERE pages > 300;
-- Livres avec un stock supérieur à 100
SELECT title, stock_quantity
FROM books
WHERE stock_quantity > 100;
-- Livres publiés entre 2000 et 2010
SELECT title, released_year
FROM books
WHERE released_year BETWEEN 2000 AND 2010;
-- Livres de certains auteurs spécifiques
SELECT title, author_fname, author_lname
FROM books
WHERE author_lname IN ('Gaiman', 'Lahiri');
-- Livres contenant le mot "the" dans le titre
SELECT title
FROM books
WHERE title LIKE '%the%';
-- Livres avec moins de 200 pages et un stock > 50
SELECT title, pages, stock_quantity
FROM books
WHERE pages < 200 AND stock_quantity > 50;
-- Livres récents (après 2010) avec un stock faible (<30)
SELECT title, released_year, stock_quantity
FROM books
WHERE released_year > 2010 AND stock_quantity < 30;
##################################
# Order by
##################################
SELECT * FROM MesLivres.books ORDER BY author_lname;
SELECT * FROM MesLivres.books ORDER BY author_lname DESC;
SELECT * FROM MesLivres.books ORDER BY released_year;
SELECT book_id, author_fname, author_lname, pages
FROM MesLivres.books ORDER BY 2 desc;
SELECT book_id, author_fname, author_lname, pages
FROM books ORDER BY author_lname, pages;
# Dan Harris vs Freida Harris
SELECT book_id, author_fname, author_lname, pages
FROM books ORDER BY author_lname, author_fname;
-- Trier les livres par année de publication (croissant)
SELECT title, released_year
FROM books
ORDER BY released_year;
-- Trier les livres par nombre de pages (décroissant)
SELECT title, pages
FROM books
ORDER BY pages DESC;
-- Trier par nom d'auteur puis par prénom
SELECT author_lname, author_fname, title
FROM books
ORDER BY author_lname, author_fname;
-- Trier par quantité en stock (du plus faible au plus élevé)
SELECT title, stock_quantity
FROM books
ORDER BY stock_quantity;
-- Trier les livres par année puis par titre
SELECT released_year, title
FROM books
ORDER BY released_year DESC, title ASC;
-- Trier les livres par nombre de pages et afficher les 5 plus longs
SELECT title, pages
FROM books
ORDER BY pages DESC
LIMIT 5;
-- Trier par auteur et année de publication
SELECT author_lname, author_fname, released_year, title
FROM books
ORDER BY author_lname, released_year DESC;
-- Trier par longueur du titre
SELECT title, pages
FROM books
ORDER BY LENGTH(title) DESC;
-- Combiner WHERE et ORDER BY
SELECT title, released_year, pages
FROM books
WHERE released_year > 2000
ORDER BY pages DESC;
##################################
# LIMIT et OFFSET
##################################
SELECT title FROM books LIMIT 3;
SELECT title FROM books LIMIT 1;
SELECT title FROM books LIMIT 10;
SELECT * FROM books LIMIT 1;
SELECT title, released_year FROM books
ORDER BY released_year DESC LIMIT 5;
SELECT title, released_year FROM books
ORDER BY released_year DESC LIMIT 1;
SELECT title, released_year FROM books
ORDER BY released_year DESC LIMIT 14;
SELECT title, released_year FROM books
ORDER BY released_year DESC LIMIT 0,5;
SELECT title, released_year FROM books
ORDER BY released_year DESC LIMIT 0,3;
SELECT title, released_year FROM books
ORDER BY released_year DESC LIMIT 1,3;
SELECT title, released_year FROM books
ORDER BY released_year DESC LIMIT 10,1;
SELECT * FROM books LIMIT 95,18446744073709551615;
SELECT title FROM books LIMIT 5;
SELECT title FROM books LIMIT 5, 123219476457;
SELECT title FROM books LIMIT 5, 50;
##################################
# LIKE
##################################
# Prénom contient 'da' n'impiorte ou dans le nom
# % symobile 1 ou plusieurs caractères
SELECT title, author_fname, author_lname, pages
FROM books
WHERE author_fname LIKE '%da%';
# Titre contient ':'
SELECT title, author_fname, author_lname, pages
FROM books
WHERE title LIKE '%:%';
# Prénom contient 4 caractères
SELECT * FROM books
WHERE author_fname LIKE '____';
# Prénom contient 3 caractères dont le 'a' comme 2e caractèrese
SELECT * FROM books
WHERE author_fname LIKE '_a_';
# Prénom contient 4 caractères dont le 'a' comme 2e caractèrese
SELECT * FROM books
WHERE author_fname LIKE '_a__';
# Prénom qui fini par la lettre n
SELECT * FROM books
WHERE author_fname LIKE '%n';
-- Livres dont le titre contient 'the'
SELECT title
FROM books
WHERE title LIKE '%the%';
-- Livres commençant par 'The'
SELECT title
FROM books
WHERE title LIKE 'The%';
-- Livres se terminant par 'stories'
SELECT title
FROM books
WHERE title LIKE '%stories';
-- Livres avec un espace dans l'author_lname
SELECT author_fname, author_lname
FROM books
WHERE author_lname LIKE '% %';
-- Livres ne contenant PAS 'the' dans le titre
SELECT title
FROM books
WHERE title NOT LIKE '%the%';
-- Livres contenant un chiffre
SELECT title
FROM books
WHERE title LIKE '%[0-9]%';
-- Titres contenant 'love'
SELECT title
FROM books
WHERE title LIKE '%love%';
-- Auteurs dont le prénom ne commence pas par 'D'
SELECT author_fname, author_lname
FROM books
WHERE author_fname NOT LIKE 'D%';
-- Livres avec exactement 3 caractères dans author_fname
SELECT author_fname, title
FROM books
WHERE author_fname LIKE '___';
-- Titres contenant 'of' au milieu
SELECT title
FROM books
WHERE title LIKE '% of %';
¶ Définition
Les fonctions de raffinement dans SQL permettent de filtrer et préciser les résultats d'une requête pour obtenir exactement les données souhaitées selon des critères spécifiques comme des motifs de texte (LIKE), des intervalles de valeurs (BETWEEN), des listes (IN) ou des conditions particulières (IS NULL).
¶ DISTINCT
La fonction DISTINCT est utilisée pour éliminer les doublons dans les résultats d'une requête SELECT. Elle permet de sélectionner les valeurs uniques d'une colonne ou d'un ensemble de colonnes dans une table.
-- Obtenir la liste unique des villes des clients
SELECT DISTINCT ville FROM clients;
-- Si plusieurs clients habitent "Paris", "Paris" n'apparaîtra qu'une fois
-- Obtenir les différentes catégories de produits
SELECT DISTINCT categorie FROM produits;
-- Exemple résultat : Électronique, Vêtements, Alimentation...
-- DISTINCT sur plusieurs colonnes (combinaisons uniques)
SELECT DISTINCT ville, pays FROM adresses;
-- Chaque combinaison ville/pays n'apparaîtra qu'une fois
-- Compter le nombre de valeurs uniques
SELECT COUNT(DISTINCT departement) FROM employes;
-- Compte le nombre de départements différents
-- DISTINCT avec une condition WHERE
SELECT DISTINCT marque FROM produits WHERE prix > 100;
-- Liste unique des marques dont au moins un produit coûte plus de 100$
-- DISTINCT combiné avec ORDER BY
SELECT DISTINCT annee FROM ventes ORDER BY annee DESC;
-- Liste des années uniques triées par ordre décroissantLa fonction DISTINCT peut être utilisée avec une ou plusieurs colonnes. Si vous souhaitez sélectionner les valeurs uniques pour un ensemble de colonnes, vous pouvez utiliser la clause DISTINCT avec la liste des colonnes séparées par une virgule.
Voici un exemple visuel:
SELECT author_lname FROM table; VS SELECT DISTINCT author_lname FROM table;
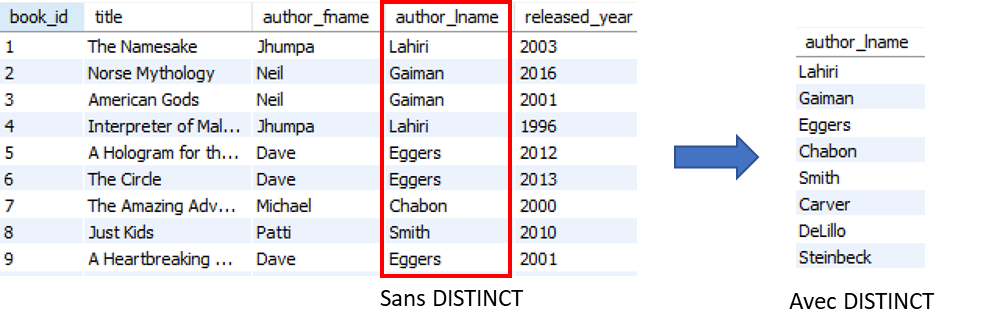
¶ WHERE
WHERE est une clause SQL qui permet de filtrer les résultats d'une requête en spécifiant une ou plusieurs conditions que les enregistrements doivent satisfaire. Voici des exemples:
-- Filtrage simple avec égalité
SELECT * FROM employes
WHERE departement = 'Marketing';
-- Comparaison numérique
SELECT * FROM produits
WHERE prix > 100;
-- Plusieurs conditions avec AND
SELECT * FROM clients
WHERE ville = 'Paris'
AND age > 25;
-- Plusieurs conditions avec OR
SELECT * FROM commandes
WHERE statut = 'en cours'
OR statut = 'en attente';
-- Combinaison de AND et OR
SELECT * FROM produits
WHERE (categorie = 'Électronique' OR categorie = 'Informatique')
AND prix < 1000;
-- Avec LIKE pour recherche partielle
SELECT * FROM clients
WHERE email LIKE '%gmail.com';
-- Avec IN pour liste de valeurs
SELECT * FROM employes
WHERE service IN ('RH', 'Comptabilité', 'Marketing');
-- Avec BETWEEN pour intervalle
SELECT * FROM commandes
WHERE date_commande BETWEEN '2024-01-01' AND '2024-12-31';
-- Avec IS NULL
SELECT * FROM clients
WHERE telephone IS NULL;
-- Avec des calculs
SELECT * FROM produits
WHERE prix * quantite > 1000;¶ ORDER BY
ORDER BY est une clause dans SQL qui permet de trier les résultats d'une requête selon une ou plusieurs colonnes spécifiées. Par défaut, ORDER BY trie les résultats en ordre croissant selon la colonne spécifiée.
- ASCENDING par défault (Alphabet: NULL…A à Z. Numéro: NULL..plus petit au plus gros)
- DESCENDING ((Alphabet: Z…A…NULL. Numéro: Grand…petit…NULL)
- ORDER BY X: trie par la Xe colonne. Exemple: ORDER BY 2 DESC;
- ORDER BY colonne1, colonne 2,…. (Colonne 1 en premier, ensuite colonne 2, …)
-- Tri simple ascendant (ASC est optionnel car c'est le tri par défaut)
SELECT * FROM employes ORDER BY salaire ASC;
SELECT * FROM employes ORDER BY salaire;
-- Tri décroissant
SELECT * FROM produits ORDER BY prix DESC;
-- Tri sur plusieurs colonnes
SELECT * FROM clients
ORDER BY pays ASC, ville DESC;
-- Trie d'abord par pays (A à Z), puis pour chaque pays, trie les villes (Z à A)
-- Tri avec WHERE
SELECT * FROM commandes
WHERE statut = 'en cours'
ORDER BY date_commande DESC;
-- Tri par position de colonne (déconseillé car moins lisible)
SELECT nom, prenom, age FROM etudiants
ORDER BY 3 DESC; -- Trie sur la 3ème colonne (age)
-- Tri avec NULL
SELECT * FROM produits
ORDER BY prix NULLS LAST; -- Place les valeurs NULL à la finVous pouvez également trier les résultats en fonction de plusieurs colonnes en spécifiant plusieurs noms de colonnes séparés par des virgules. Par exemple:
SELECT * FROM books ORDER BY released_year DESC, author_lname ASC;¶ LIMIT et OFFSET
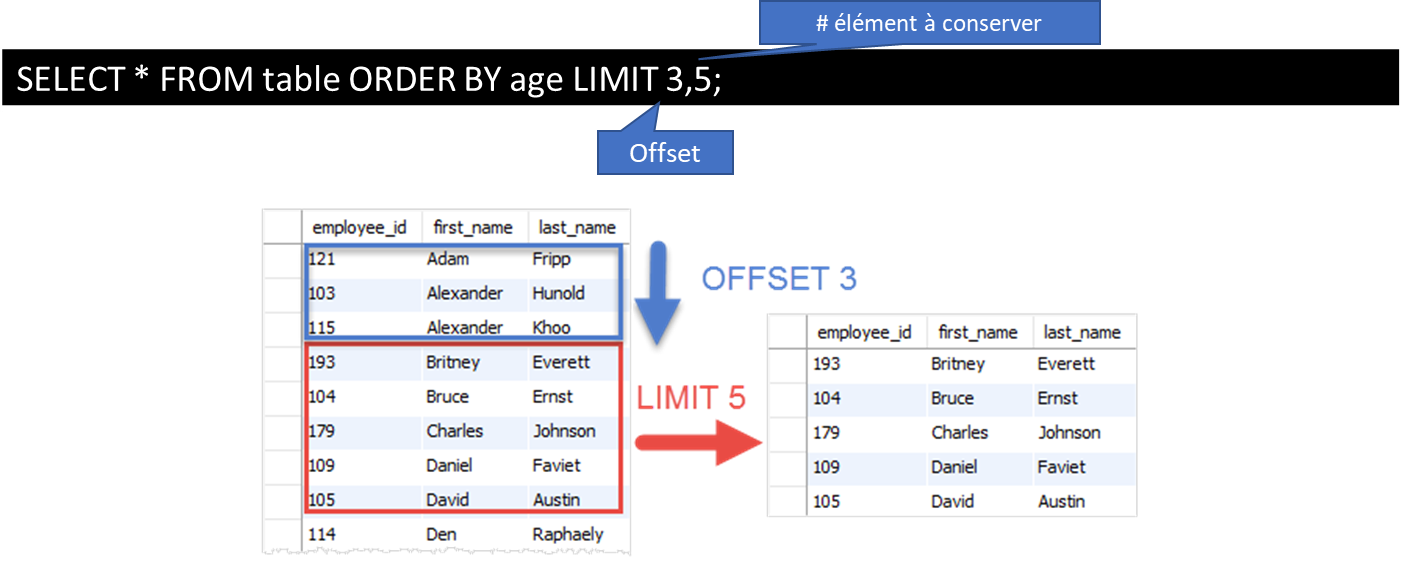
LIMIT est une clause dans SQL qui permet de limiter le nombre de résultats retournés par une requête SELECT. Cette clause est souvent utilisée en conjonction avec ORDER BY pour récupérer les premiers résultats triés.
Par exemple, si vous avez une table de noms et d'âges et que vous voulez récupérer les 10 premiers résultats triés par âge, vous pouvez utiliser la requête suivante :
SELECT * FROM table_nom_age ORDER BY age LIMIT 10;Cela retournera les 10 premiers résultats triés par âge. Si la table contient moins de 10 enregistrements, elle renverra simplement tous les résultats.
Vous pouvez également utiliser OFFSET pour spécifier le nombre de résultats à ignorer avant de commencer à récupérer des résultats. Par exemple, si vous voulez récupérer les résultats 11 à 20 triés par âge, vous pouvez utiliser la requête suivante :
SELECT * FROM table_nom_age ORDER BY age LIMIT 10 OFFSET 10;Cela retournera les 10 résultats suivants triés par âge, en ignorant les 10 premiers résultats.
LIMIT peut être utilisé avec deux paramètres. Dans ce cas, le premier paramètre représente le OFFSET et le 2e paramètre représente le nombre d’élément à conserver:
SELECT * FROM table ORDER BY age LIMIT 3,5;
¶ LIKE
LIKE est un opérateur SQL qui permet de rechercher des motifs dans une chaîne de caractères en utilisant des caractères spéciaux (% pour remplacer plusieurs caractères et _ pour un seul caractère). L'opérateur LIKE est généralement utilisé en conjonction avec la clause WHERE pour filtrer les résultats d'une requête. La syntaxe générale est la suivante :
SELECT colonnes FROM table WHERE colonne LIKE 'motif';Le motif spécifié est une chaîne de caractères qui peut contenir des caractères spéciaux pour définir un modèle.
Les deux caractères spéciaux les plus couramment utilisés sont le symbole de pourcentage (%) et le symbole de soulignement (_) pour le nombre de caractère (ex.: _ _ _ représente 3 caractères). Le symbole de pourcentage représente zéro, un ou plusieurs caractères.
Par exemple, si vous recherchez tous les enregistrements dans une table qui contiennent le mot "chat" dans la colonne "nom", vous pouvez utiliser la requête suivante :
SELECT * FROM table_animaux WHERE nom LIKE '%chat%';Cela retournera tous les enregistrements qui ont la chaîne "chat" quelque part dans la colonne "nom".
Il est important de noter que l'opérateur LIKE peut ralentir les requêtes sur des tables avec de nombreux enregistrements, car la recherche de motifs peut être intensive en termes de ressources.
Voici d'autres exemples de l'utilisation du LIKE
-- Trouve les prénoms qui commencent par 'Ma'
SELECT * FROM utilisateurs WHERE prenom LIKE 'Ma%';
-- Exemple: Martin, Marie, Marc...
-- Trouve les noms qui finissent par 'son'
SELECT * FROM clients WHERE nom LIKE '%son';
-- Exemple: Wilson, Thompson, Johnson...
-- Trouve les villes qui contiennent 'ville'
SELECT * FROM adresses WHERE ville LIKE '%ville%';
-- Exemple: Deauville, Villeneuve, Belleville...
-- Trouve les mots avec exactement 5 lettres
SELECT * FROM mots WHERE mot LIKE '_____';
-- Exemple: paris, table, chien...
-- Trouve les emails qui commencent par 'j' et finissent par '@gmail.com'
SELECT * FROM contacts WHERE email LIKE 'j%@gmail.com';
-- Exemple: jean@gmail.com, julie@gmail.com...¶ NOT LIKE
NOT LIKE est une commande de comparaison utilisée pour filtrer les enregistrements d'une table selon un motif de caractères spécifique.
La commande NOT LIKE est utilisée pour sélectionner toutes les lignes d'une table qui ne correspondent pas à un motif de caractères spécifique. Le mot-clé NOT est utilisé pour inverser la correspondance.
Voici un exemple de la façon dont la commande NOT LIKE est utilisée dans une requête SQL
SELECT *
FROM products
WHERE product_name NOT LIKE '%papier%';
Dans cet exemple, la requête sélectionne tous les produits de la table "products" dont le nom ne contient pas le mot "papier". Le caractère "%" est utilisé pour représenter un ou plusieurs caractères qui peuvent apparaître avant ou après le mot "papier".
En général, la commande NOT LIKE est utilisée en conjonction avec le caractère générique "%" pour effectuer une recherche de motif plus complexe qui ne correspond pas à une chaîne de caractères spécifique.
¶ Les opérateurs de comparaison
¶ Script
Create database Meslivres;
use Meslivres;
CREATE TABLE books
(
book_id INT AUTO_INCREMENT,
title VARCHAR(100),
author_fname VARCHAR(100),
author_lname VARCHAR(100),
released_year INT,
stock_quantity INT,
pages INT,
PRIMARY KEY(book_id)
);
INSERT INTO books (title, author_fname, author_lname, released_year, stock_quantity, pages)
VALUES
('The Namesake', 'Jhumpa', 'Lahiri', 2003, 32, 291),
('Norse Mythology', 'Neil', 'Gaiman',2016, 43, 304),
('American Gods', 'Neil', 'Gaiman', 2001, 12, 465),
('Interpreter of Maladies', 'Jhumpa', 'Lahiri', 1996, 97, 198),
('A Hologram for the King: A Novel', 'Dave', 'Eggers', 2012, 154, 352),
('The Circle', 'Dave', 'Eggers', 2013, 26, 504),
('The Amazing Adventures of Kavalier & Clay', 'Michael', 'Chabon', 2000, 68, 634),
('Just Kids', 'Patti', 'Smith', 2010, 55, 304),
('A Heartbreaking Work of Staggering Genius', 'Dave', 'Eggers', 2001, 104, 437),
('Coraline', 'Neil', 'Gaiman', 2003, 100, 208),
('What We Talk About When We Talk About Love: Stories', 'Raymond', 'Carver', 1981, 23, 176),
("Where I'm Calling From: Selected Stories", 'Raymond', 'Carver', 1989, 12, 526),
('White Noise', 'Don', 'DeLillo', 1985, 49, 320),
('Cannery Row', 'John', 'Steinbeck', 1945, 95, 181),
('Oblivion: Stories', 'David', NULL, 2004, 172, 329),
('Consider the Lobster', NULL, 'Foster Wallace', 2005, 92, 343),
('10% Happier', 'Dan', 'Harris', NULL, 29, 256),
('fake_book', 'Freida', 'Harris', 2001, NULL, 428),
('Lincoln In The Bardo', 'George', 'Saunders', 2017, 1000, NULL);
##################################
# Greater than // Greater than or equal
##################################
-- Exemple 1 : Comparaison avec >
-- Trouver les livres ayant plus de 400 pages
SELECT title, pages
FROM books
WHERE pages > 400;
-- Résultat :
-- American Gods | 465
-- The Circle | 504
-- The Amazing Adventures of Kavalier & Clay | 634
-- Where I'm Calling From: Selected Stories | 526
-- fake_book | 428
-- Exemple 2 : Comparaison avec >=
-- Trouver les livres publiés en 2004 ou après
SELECT title, released_year
FROM books
WHERE released_year >= 2004;
-- Résultat :
-- Norse Mythology | 2016
-- Oblivion: Stories | 2004
-- Consider the Lobster | 2005
-- Lincoln In The Bardo | 2017
-- Exemple 3 : Comparaison mixte > et >=
-- Trouver les livres ayant plus de 300 pages ET un stock supérieur ou égal à 100
SELECT title, pages, stock_quantity
FROM books
WHERE pages > 300
AND stock_quantity >= 100;
-- Résultat :
-- A Hologram for the King: A Novel | 352 | 154
-- The Circle | 504 | 26
-- The Amazing Adventures of Kavalier & Clay | 634 | 68
-- A Heartbreaking Work of Staggering Genius | 437 | 104
-- Oblivion: Stories | 329 | 172
##################################
# Less than // Less than or equal
##################################
-- Exemple 1 : Comparaison avec
-- Trouver les livres ayant moins de 300 pages
SELECT title, pages
FROM books
WHERE pages < 300;
-- Résultat :
-- The Namesake | 291
-- Interpreter of Maladies | 198
-- Coraline | 208
-- What We Talk About When We Talk About Love: Stories | 176
-- Cannery Row | 181
-- Exemple 2 : Comparaison avec <=
-- Trouver les livres publiés en 2000 ou avant
SELECT title, released_year
FROM books
WHERE released_year <= 2000;
-- Résultat :
-- Interpreter of Maladies | 1996
-- The Amazing Adventures of Kavalier & Clay | 2000
-- What We Talk About When We Talk About Love: Stories | 1981
-- Where I'm Calling From: Selected Stories | 1989
-- White Noise | 1985
-- Cannery Row | 1945
-- Exemple 3 : Comparaison mixte < et <=
-- Trouver les livres ayant moins de 300 pages ET un stock inférieur ou égal à 50
SELECT title, pages, stock_quantity
FROM books
WHERE pages < 300
AND stock_quantity <= 50;
-- Résultat :
-- What We Talk About When We Talk About Love: Stories | 176 | 23
##################################
# AND
##################################
-- Exemple 1 : Trouver les livres de Neil Gaiman publiés après 2010
SELECT title, author_fname, author_lname, released_year
FROM books
WHERE author_fname = 'Neil'
AND author_lname = 'Gaiman'
AND released_year > 2010;
-- Résultat :
-- Norse Mythology | Neil | Gaiman | 2016
-- Exemple 2 : Trouver les livres qui ont plus de 300 pages ET plus de 100 exemplaires en stock
SELECT title, pages, stock_quantity
FROM books
WHERE pages > 300
AND stock_quantity > 100;
-- Résultat :
-- A Hologram for the King: A Novel | 352 | 154
-- Lincoln In The Bardo | NULL | 1000 (Note: celui-ci n'apparaîtra pas car pages est NULL)
-- Exemple 3 : Trouver les livres publiés entre 2000 et 2005 avec moins de 50 exemplaires en stock
SELECT title, released_year, stock_quantity
FROM books
WHERE released_year BETWEEN 2000 AND 2005
AND stock_quantity < 50;
-- Résultat :
-- American Gods | 2001 | 12
-- The Circle | 2013 | 26
##################################
# OR
##################################
-- Exemple 1 : Trouver les livres de Neil Gaiman OU de Dave Eggers
SELECT title, author_fname, author_lname
FROM books
WHERE author_fname = 'Neil'
OR author_fname = 'Dave';
-- Résultat :
-- Norse Mythology | Neil | Gaiman
-- American Gods | Neil | Gaiman
-- A Hologram for the King: A Novel | Dave | Eggers
-- The Circle | Dave | Eggers
-- Coraline | Neil | Gaiman
-- A Heartbreaking Work of Staggering Genius | Dave | Eggers
-- Exemple 2 : Trouver les livres avec soit moins de 200 pages, soit plus de 500 pages
SELECT title, pages
FROM books
WHERE pages < 200
OR pages > 500;
-- Résultat :
-- Interpreter of Maladies | 198
-- The Amazing Adventures of Kavalier & Clay | 634
-- What We Talk About When We Talk About Love: Stories | 176
-- Where I'm Calling From: Selected Stories | 526
-- Cannery Row | 181
-- Exemple 3 : Trouver les livres publiés avant 1950 OU après 2015
SELECT title, released_year
FROM books
WHERE released_year < 1950
OR released_year > 2015;
-- Résultat :
-- Norse Mythology | 2016
-- Cannery Row | 1945
-- Lincoln In The Bardo | 2017
##################################
# XOR
##################################
-- Exemple 1 : Trouver les livres qui ont soit plus de 500 pages, soit plus de 100 en stock, mais pas les deux
SELECT title, pages, stock_quantity
FROM books
WHERE (pages > 500) XOR (stock_quantity > 100);
-- Résultat :
-- A Hologram for the King: A Novel | 352 | 154
-- The Amazing Adventures of Kavalier & Clay | 634 | 68
-- Where I'm Calling From: Selected Stories | 526 | 12
-- Oblivion: Stories | 329 | 172
-- Lincoln In The Bardo | NULL | 1000
-- Exemple 2 : Trouver les livres publiés soit avant 1990, soit ayant un titre de plus de 30 caractères, mais pas les deux
SELECT title, released_year
FROM books
WHERE (released_year < 1990) XOR (LENGTH(title) > 30);
-- Résultat :
-- A Hologram for the King: A Novel | 2012
-- The Amazing Adventures of Kavalier & Clay | 2000
-- A Heartbreaking Work of Staggering Genius | 2001
-- What We Talk About When We Talk About Love: Stories | 1981
-- Cannery Row | 1945
-- Exemple 3 : Trouver les livres qui ont soit l'auteur_fname NULL soit l'auteur_lname NULL, mais pas les deux
SELECT title, author_fname, author_lname
FROM books
WHERE (author_fname IS NULL) XOR (author_lname IS NULL);
-- Résultat :
-- Oblivion: Stories | David | NULL
-- Consider the Lobster | NULL | Foster Wallace
##################################
# NOT EQUAL
##################################
-- Exemple 1 : Trouver tous les livres qui ne sont pas de Neil Gaiman
SELECT title, author_fname, author_lname
FROM books
WHERE author_fname != 'Neil';
-- ou: WHERE author_fname <> 'Neil';
-- Résultat :
-- The Namesake | Jhumpa | Lahiri
-- Interpreter of Maladies | Jhumpa | Lahiri
-- A Hologram for the King: A Novel | Dave | Eggers
-- The Circle | Dave | Eggers
-- The Amazing Adventures of Kavalier & Clay | Michael | Chabon
-- Just Kids | Patti | Smith
-- A Heartbreaking Work of Staggering Genius | Dave | Eggers
-- What We Talk About When We Talk About Love: Stories | Raymond | Carver
-- Where I'm Calling From: Selected Stories | Raymond | Carver
-- White Noise | Don | DeLillo
-- Cannery Row | John | Steinbeck
-- Oblivion: Stories | David | NULL
-- Consider the Lobster | NULL | Foster Wallace
-- 10% Happier | Dan | Harris
-- fake_book | Freida | Harris
-- Lincoln In The Bardo | George | Saunders
-- Exemple 2 : Trouver les livres qui n'ont pas été publiés en 2003
SELECT title, released_year
FROM books
WHERE released_year != 2003;
-- Résultat :
-- Norse Mythology | 2016
-- American Gods | 2001
-- Interpreter of Maladies | 1996
-- A Hologram for the King: A Novel | 2012
-- The Circle | 2013
-- The Amazing Adventures of Kavalier & Clay | 2000
-- Just Kids | 2010
-- A Heartbreaking Work of Staggering Genius | 2001
-- What We Talk About When We Talk About Love: Stories | 1981
-- Where I'm Calling From: Selected Stories | 1989
-- White Noise | 1985
-- Cannery Row | 1945
-- Oblivion: Stories | 2004
-- Consider the Lobster | 2005
-- fake_book | 2001
-- Lincoln In The Bardo | 2017
-- Exemple 3 : Trouver les livres qui n'ont pas exactement 304 pages
SELECT title, pages
FROM books
WHERE pages != 304;
-- Résultat :
-- The Namesake | 291
-- American Gods | 465
-- Interpreter of Maladies | 198
-- A Hologram for the King: A Novel | 352
-- The Circle | 504
-- The Amazing Adventures of Kavalier & Clay | 634
-- A Heartbreaking Work of Staggering Genius | 437
-- Coraline | 208
-- What We Talk About When We Talk About Love: Stories | 176
-- Where I'm Calling From: Selected Stories | 526
-- White Noise | 320
-- Cannery Row | 181
-- Oblivion: Stories | 329
-- Consider the Lobster | 343
-- 10% Happier | 256
-- fake_book | 428
##################################
# BETWEEN // NOT BETWEEN
##################################
-- Exemple 1 : Trouver les livres publiés entre 2000 et 2005 inclus
SELECT title, released_year
FROM books
WHERE released_year BETWEEN 2000 AND 2005;
-- Résultat :
-- The Namesake | 2003
-- American Gods | 2001
-- The Amazing Adventures of Kavalier & Clay | 2000
-- A Heartbreaking Work of Staggering Genius | 2001
-- Coraline | 2003
-- Oblivion: Stories | 2004
-- fake_book | 2001
-- Exemple 2 : Trouver les livres ayant entre 300 et 400 pages
SELECT title, pages
FROM books
WHERE pages BETWEEN 300 AND 400;
-- Résultat :
-- Norse Mythology | 304
-- A Hologram for the King: A Novel | 352
-- Just Kids | 304
-- White Noise | 320
-- Oblivion: Stories | 329
-- Consider the Lobster | 343
-- Lincoln In The Bardo | 367
-- Exemple 3 : Trouver les livres ayant entre 50 et 100 exemplaires en stock
SELECT title, stock_quantity
FROM books
WHERE stock_quantity BETWEEN 50 AND 100;
-- Résultat :
-- Interpreter of Maladies | 97
-- The Amazing Adventures of Kavalier & Clay | 68
-- Just Kids | 55
-- Cannery Row | 95
-- Consider the Lobster | 92
##################################
# IN
##################################
-- Exemple 1 : Trouver les livres écrits par Neil Gaiman ou Dave Eggers
SELECT title, author_fname, author_lname
FROM books
WHERE author_fname IN ('Neil', 'Dave');
-- Résultat :
-- Norse Mythology | Neil | Gaiman
-- American Gods | Neil | Gaiman
-- A Hologram for the King: A Novel | Dave | Eggers
-- The Circle | Dave | Eggers
-- Coraline | Neil | Gaiman
-- A Heartbreaking Work of Staggering Genius | Dave | Eggers
-- Exemple 2 : Trouver les livres publiés en 2003, 2004, ou 2005
SELECT title, released_year
FROM books
WHERE released_year IN (2003, 2004, 2005);
-- Résultat :
-- The Namesake | 2003
-- Coraline | 2003
-- Oblivion: Stories | 2004
-- Consider the Lobster | 2005
-- Exemple 3 : Trouver les livres ayant exactement 304, 329, ou 343 pages
SELECT title, pages
FROM books
WHERE pages IN (304, 329, 343);
-- Résultat :
-- Norse Mythology | 304
-- Just Kids | 304
-- Oblivion: Stories | 329
-- Consider the Lobster | 343
##################################
# IS NULL
##################################
-- Exemple 1 : Trouver les livres où le prénom de l'auteur est NULL
SELECT title, author_fname, author_lname
FROM books
WHERE author_fname IS NULL;
-- Résultat :
-- Consider the Lobster | NULL | Foster Wallace
-- Exemple 2 : Trouver les livres où soit le nombre de pages, soit la quantité en stock est NULL
SELECT title, pages, stock_quantity
FROM books
WHERE pages IS NULL
OR stock_quantity IS NULL;
-- Résultat :
-- fake_book | 428 | NULL
-- Lincoln In The Bardo | NULL | 1000
-- Exemple 3 : Comparer les livres avec et sans année de publication
SELECT title,
CASE
WHEN released_year IS NULL THEN 'Année inconnue'
ELSE CAST(released_year AS VARCHAR)
END AS année
FROM books
ORDER BY
CASE WHEN released_year IS NULL THEN 1 ELSE 0 END,
released_year;
-- Résultat :
-- Cannery Row | 1945
-- What We Talk About When We Talk About Love: Stories | 1981
-- White Noise | 1985
-- Where I'm Calling From: Selected Stories | 1989
-- Interpreter of Maladies | 1996
-- The Amazing Adventures of Kavalier & Clay | 2000
-- American Gods | 2001
-- A Heartbreaking Work of Staggering Genius | 2001
-- fake_book | 2001
-- The Namesake | 2003
-- Coraline | 2003
-- Oblivion: Stories | 2004
-- Consider the Lobster | 2005
-- Just Kids | 2010
-- A Hologram for the King: A Novel | 2012
-- The Circle | 2013
-- Norse Mythology | 2016
-- Lincoln In The Bardo | 2017
-- 10% Happier | Année inconnue
##################################
# CASE
##################################
-- Exemple 1 : Classifier les livres selon leur nombre de pages
SELECT title, pages,
CASE
WHEN pages < 200 THEN 'Très court'
WHEN pages < 300 THEN 'Court'
WHEN pages < 400 THEN 'Moyen'
WHEN pages < 500 THEN 'Long'
WHEN pages >= 500 THEN 'Très long'
ELSE 'Non spécifié'
END AS longueur
FROM books;
-- Résultat :
-- The Namesake | 291 | Court
-- Norse Mythology | 304 | Moyen
-- American Gods | 465 | Long
-- Interpreter of Maladies | 198 | Très court
-- A Hologram for the King: A Novel | 352 | Moyen
-- The Circle | 504 | Très long
-- The Amazing Adventures of Kavalier & Clay | 634 | Très long
-- Just Kids | 304 | Moyen
-- A Heartbreaking Work of Staggering Genius | 437 | Long
-- Coraline | 208 | Court
-- What We Talk About When We Talk About Love: Stories | 176 | Très court
-- Where I'm Calling From: Selected Stories | 526 | Très long
-- White Noise | 320 | Moyen
-- Cannery Row | 181 | Très court
-- Oblivion: Stories | 329 | Moyen
-- Consider the Lobster | 343 | Moyen
-- 10% Happier | 256 | Court
-- fake_book | 428 | Long
-- Lincoln In The Bardo | NULL | Non spécifié
-- Exemple 2 : Classifier les livres selon leur période de publication
SELECT title, released_year,
CASE
WHEN released_year < 1980 THEN 'Classique'
WHEN released_year < 2000 THEN 'Moderne'
WHEN released_year < 2010 THEN 'Contemporain'
WHEN released_year >= 2010 THEN 'Récent'
ELSE 'Date inconnue'
END AS époque,
author_fname,
author_lname
FROM books;
-- Résultat :
-- The Namesake | 2003 | Contemporain | Jhumpa | Lahiri
-- Norse Mythology | 2016 | Récent | Neil | Gaiman
-- American Gods | 2001 | Contemporain | Neil | Gaiman
-- Interpreter of Maladies | 1996 | Moderne | Jhumpa | Lahiri
-- A Hologram for the King: A Novel | 2012 | Récent | Dave | Eggers
-- The Circle | 2013 | Récent | Dave | Eggers
-- The Amazing Adventures of Kavalier & Clay | 2000 | Contemporain | Michael | Chabon
-- Just Kids | 2010 | Récent | Patti | Smith
-- [... et ainsi de suite]
-- Exemple 3 : Classifier les livres selon leur stock et donner des recommandations
SELECT
title,
stock_quantity,
CASE
WHEN stock_quantity <= 20 THEN 'URGENT: Réapprovisionner'
WHEN stock_quantity <= 50 THEN 'Commander bientôt'
WHEN stock_quantity <= 100 THEN 'Stock OK'
WHEN stock_quantity > 100 THEN 'Stock abondant'
ELSE 'Stock non spécifié'
END AS statut_stock,
CASE
WHEN stock_quantity <= 20 THEN 50
WHEN stock_quantity <= 50 THEN 30
WHEN stock_quantity <= 100 THEN 20
ELSE 0
END AS quantité_à_commander
FROM books;
-- Résultat :
-- American Gods | 12 | URGENT: Réapprovisionner | 50
-- Where I'm Calling From: Selected Stories | 12 | URGENT: Réapprovisionner | 50
-- What We Talk About When We Talk About Love: Stories | 23 | Commander bientôt | 30
-- The Circle | 26 | Commander bientôt | 30
-- 10% Happier | 29 | Commander bientôt | 30
-- The Namesake | 32 | Commander bientôt | 30
-- Norse Mythology | 43 | Commander bientôt | 30
-- White Noise | 49 | Commander bientôt | 30
-- Just Kids | 55 | Stock OK | 20
-- [... et ainsi de suite]¶ Opérateurs logiques
Les opérateurs logiques ("logical operators" en anglais) sont des opérateurs utilisés pour combiner des expressions booléennes et produire un résultat basé sur la logique booléenne. Les opérateurs logiques les plus couramment utilisés dans MySQL sont:
AND (aussi écrit "&&"): cet opérateur logique renvoie TRUE si et seulement si les deux expressions qu'il relie sont toutes les deux TRUE. Par exemple, la condition "age > 18 AND gender = 'M'" renverra TRUE uniquement si l'âge de la personne est supérieur à 18 ans ET si elle est de sexe masculin.
OR (aussi écrit "||"): cet opérateur logique renvoie TRUE si au moins l'une des expressions qu'il relie est TRUE. Par exemple, la condition "age > 18 OR gender = 'M'" renverra TRUE si la personne est soit de sexe masculin, soit si son âge est supérieur à 18 ans.
NOT (aussi écrit "!"): cet opérateur logique inverse la valeur de l'expression qu'il précède. Par exemple, la condition "NOT age > 18" renverra TRUE si l'âge de la personne est inférieur ou égal à 18 ans.
XOR: cet opérateur logique qui renvoie TRUE uniquement si une condition est vraie et l'autre est fausse (mais pas les deux en même temps).
Il est important de noter que les expressions qui sont combinées avec des opérateurs logiques doivent être des expressions booléennes, c'est-à-dire qu'elles doivent évaluer à TRUE ou FALSE. Les opérateurs logiques peuvent être utilisés dans les requêtes SELECT, UPDATE, DELETE, et dans d'autres instructions SQL pour filtrer les résultats en fonction de critères de sélection spécifiques.

Les opérateurs logiques sont basés sur les tables de vérité des composantes électroniques:
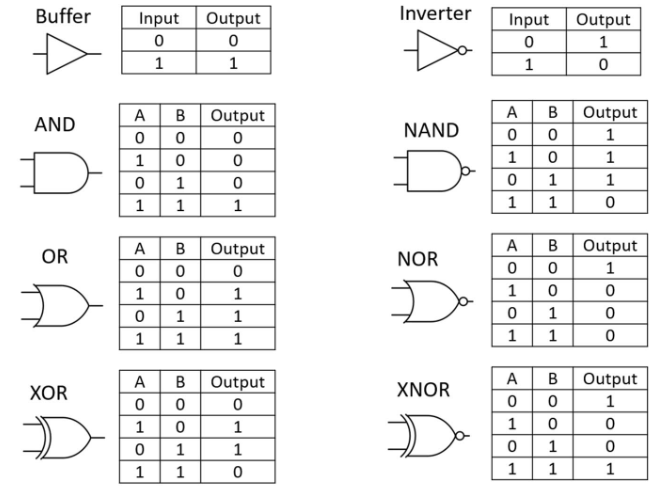
Pour plus d'info sur les opérateurs logiques: https://dev.mysql.com/doc/refman/8.0/en/logical-operators.html
Pour plus d'info sur les opérateurs de comparaison: https://dev.mysql.com/doc/refman/8.0/en/comparison-operators.html
¶ AND (&&)
AND est utilisé pour combiner des conditions dans une requête SQL. L'opérateur "AND" permet d'exécuter une requête uniquement si toutes les conditions spécifiées sont vraies. Voici un exemple de l'utilisation de l'opérateur "AND" dans une requête SELECT :
SELECT *
FROM products
WHERE price < 10 AND category = 'Electronics';
Dans cet exemple, l'opérateur "AND" est utilisé pour combiner deux conditions : la première condition est que le prix doit être inférieur à 10 et la deuxième condition est que la catégorie doit être "Electronics". Les deux conditions doivent être satisfaites pour que la requête renvoie des résultats.
Prendre note que l’opérateur AND peut aussi renvoyer valeur booléenne (TRUE=1 or FALSE=0).
¶ OR (||)
OR est utilisé pour combiner des conditions dans une requête SQL. L'opérateur "OR" permet d'exécuter une requête si au moins l'une des conditions spécifiées est vraie. Voici un exemple de l'utilisation de l'opérateur "OR" dans une requête SELECT :
SELECT *
FROM products
WHERE price < 10 OR category = 'Electronics';
Dans cet exemple, la requête sélectionne tous les produits dont le prix est inférieur à 10 ou dont la catégorie est "Electronics". L'opérateur "OR" est utilisé pour combiner deux conditions : la première condition est que le prix doit être inférieur à 10 et la deuxième condition est que la catégorie doit être "Electronics". Si l'une des conditions est vraie, la requête renvoie des résultats.
L'opérateur "OR" peut également être utilisé en conjonction avec l'opérateur "AND" pour créer des expressions conditionnelles plus complexes. Par exemple :
SELECT *
FROM products
WHERE (price < 10 AND category = 'Electronics') OR (price >= 50 AND category = 'Clothing');
Dans cet exemple, la requête sélectionne tous les produits de la catégorie "Electronics" dont le prix est inférieur à 10 ou tous les produits de la catégorie "Clothing" dont le prix est supérieur ou égal à 50. Les deux conditions entre parenthèses sont combinées avec l'opérateur "OR", tandis que les conditions à l'intérieur de chaque paire de parenthèses sont combinées avec l'opérateur "AND".
Il est important de noter que l'utilisation excessive de l'opérateur "OR" peut ralentir les performances de la requête, car MySQL doit évaluer toutes les conditions possibles avant de renvoyer les résultats. Il est recommandé de limiter l'utilisation de l'opérateur "OR" autant que possible pour des requêtes optimisées.
¶ XOR (^)
En MySQL, XOR (OU exclusif) est un opérateur logique qui retourne :
- 1 (vrai) si exactement une des deux expressions est vraie, mais pas les deux
- 0 (faux) si les deux expressions sont vraies ou si les deux sont fausses
-- Utilisation du mot-clé XOR
SELECT expression1 XOR expression2
-- Ou avec l'opérateur ^
SELECT expression1 ^ expression2
XOR est particulièrement utile dans les conditions WHERE quand vous voulez vous assurer qu'une seule condition parmi deux est vraie
¶ EQAL (=)
L'opérateur EQUAL (=) dans MySQL est utilisé pour tester l'égalité entre deux valeurs ou expressions.
-- Égalité simple
SELECT * FROM employes
WHERE departement = 'Marketing';
-- Égalité avec un nombre
SELECT * FROM produits
WHERE prix = 100;
-- Multiple conditions d'égalité
SELECT * FROM clients
WHERE ville = 'Paris'
AND statut = 'VIP';
-- Dans une mise à jour
UPDATE commandes
SET statut = 'terminé'
WHERE id = 1234;
-- Comparaison avec NULL (incorrect)
-- NE PAS FAIRE: SELECT * FROM clients WHERE telephone = NULL
-- FAIRE plutôt: SELECT * FROM clients WHERE telephone IS NULL
¶ GREATER THAN (>)
GREATER THAN est un opérateur de comparaison utilisé pour vérifier si une valeur dans une colonne est supérieure à une autre valeur ou à une expression. L'opérateur ">" est utilisé pour représenter "GREATER THAN". Il peut être utilisé dans une instruction SELECT, UPDATE ou DELETE pour filtrer les enregistrements en fonction de la condition spécifiée.
Voici un exemple de la façon dont l'opérateur "GREATER THAN" est utilisé dans une requête SELECT :
SELECT *
FROM products
WHERE price > 10;Dans cet exemple, la requête sélectionne tous les produits de la table "products" dont le prix est supérieur à 10. L'opérateur ">" est utilisé pour représenter la condition que le prix doit être supérieur à 10.
Prendre note que la l’opérateur GREATER THAN peut aussi renvoyer valeur booléenne (TRUE=1 or FALSE=0).
SELECT 99 > 1;
SELECT 1 > NULL¶ GREATER THAN OR EQUAL (>=)
L'opérateur GREATER THAN OR EQUAL (>=) dans MySQL compare deux valeurs en retournant vrai si la première valeur est supérieure ou égale à la seconde. Voici des exemples:
-- Prix supérieur ou égal à 100
SELECT * FROM produits
WHERE prix >= 100;
-- Age supérieur ou égal à 18
SELECT * FROM clients
WHERE age >= 18;
-- Date supérieure ou égale
SELECT * FROM commandes
WHERE date_commande >= '2024-01-01';
-- Combiné avec d'autres conditions
SELECT * FROM employes
WHERE salaire >= 3000
AND experience >= 5;
Points importants :
- = inclut la valeur de comparaison (contrairement à >)
- Fonctionne avec les nombres, dates, et chaînes de caractères
- Peut être utilisé dans WHERE, HAVING, et conditions de JOIN
¶ LESS THAN (<)
LESS THAN est un opérateur de comparaison utilisé pour vérifier si une valeur dans une colonne est inférieure à une autre valeur ou à une expression. L'opérateur "<" est utilisé pour représenter "LESS THAN". Il peut être utilisé dans une instruction SELECT, UPDATE ou DELETE pour filtrer les enregistrements en fonction de la condition spécifiée.
Voici un exemple de la façon dont l'opérateur "LESS THAN" est utilisé dans une requête SELECT :
SELECT *
FROM products
WHERE price < 10;¶ LESS THAN OR EQAL(<=)
L'opérateur LESS THAN OR EQUAL (<=) dans MySQL compare deux valeurs en retournant vrai si la première valeur est inférieure ou égale à la seconde.
-- Prix inférieur ou égal à 50
SELECT * FROM produits
WHERE prix <= 50;
-- Âge inférieur ou égal à 25
SELECT * FROM utilisateurs
WHERE age <= 25;
-- Date inférieure ou égale
SELECT * FROM commandes
WHERE date_commande <= '2024-03-31';
-- Avec des calculs
SELECT * FROM ventes
WHERE quantite * prix <= 1000;
-- Combiné avec d'autres conditions
SELECT * FROM employes
WHERE salaire <= 5000
AND experience <= 3;
Points importants :
- <= inclut la valeur de comparaison
- Fonctionne avec les nombres, dates et chaînes
- Souvent utilisé dans les conditions de filtrage
¶ NOT EQUAL (<> ou !=)
"NOT EQUAL" est un opérateur de comparaison utilisé pour vérifier si deux valeurs sont différentes l'une de l'autre. Le symbole utilisé pour "not equal" est "<>" ou "!=". Voici différents exemples de NOT EQUAL:
-- Utilisant <>
SELECT * FROM produits
WHERE categorie <> 'Électronique';
-- Utilisant != (alternative à <>)
SELECT * FROM employes
WHERE departement != 'Marketing';
-- Avec NOT
SELECT * FROM clients
WHERE NOT ville = 'Paris';
-- Combiné avec d'autres conditions
SELECT * FROM commandes
WHERE statut != 'annulé'
AND montant > 100;
-- Avec IS NOT
SELECT * FROM utilisateurs
WHERE email IS NOT NULL;¶ BETWEEN
L'opérateur BETWEEN est utilisé dans MySQL pour sélectionner des valeurs dans un intervalle donné. Il permet de spécifier un intervalle de valeurs entre une borne inférieure et une borne supérieure, et de récupérer toutes les lignes dont la valeur de la colonne se trouve dans cet intervalle. Voici un exemple d'utilisation de l'opérateur BETWEEN dans une requête SELECT:
SELECT *
FROM employees
WHERE salary BETWEEN 50000 AND 100000;Dans cet exemple, la requête sélectionne tous les employés dont le salaire se situe entre 50000 et 100000, inclusivement.
Il est important de noter que l'opérateur BETWEEN inclut les bornes de l'intervalle dans la sélection, c'est-à-dire que les valeurs égales à la borne inférieure et à la borne supérieure sont incluses dans le résultat. Il est également possible d'utiliser l'opérateur NOT BETWEEN pour sélectionner toutes les lignes dont la valeur de la colonne ne se situe pas dans l'intervalle spécifié.
Voici d'autres exemples de BETWEEN:
-- Trouver les produits dont le prix est entre 10 et 50 euros
SELECT * FROM produits WHERE prix BETWEEN 10 AND 50;
-- Sélectionner les commandes passées entre deux dates
SELECT * FROM commandes
WHERE date_commande BETWEEN '2024-01-01' AND '2024-03-31';
-- Trouver les employés dont le salaire est entre 2000 et 3000
SELECT * FROM employes
WHERE salaire BETWEEN 2000 AND 3000;
Note importante : BETWEEN inclut les valeurs limites (c'est-à-dire que "BETWEEN 10 AND 50" inclut 10 et 50).
¶ NOT BETWEEN
L'opérateur NOT BETWEEN est utilisé en SQL pour sélectionner des valeurs en dehors d'un intervalle donné. Il fonctionne de manière similaire à l'opérateur BETWEEN, mais sélectionne toutes les lignes dont la valeur de la colonne ne se situe pas dans l'intervalle spécifié. Voici un exemple :
SELECT *
FROM employees
WHERE salary NOT BETWEEN 50000 AND 100000;
Dans cet exemple, la requête sélectionne tous les employés dont le salaire ne se situe pas entre 50000 et 100000, exclusivement.
Il est important de noter que l'utilisation de l'opérateur NOT BETWEEN peut être utile pour sélectionner toutes les lignes qui se situent en dehors d'un intervalle spécifié. Cependant, il peut également être utile de considérer l'utilisation de l'opérateur NOT pour inverser une condition existante plutôt que d'utiliser l'opérateur NOT BETWEEN.
¶ IN
L'opérateur IN est utilisé dans MySQL pour comparer une valeur à une liste de valeurs ou à un sous-ensemble de résultats d'une sous-requête. Il permet de simplifier les requêtes qui impliquent une comparaison à plusieurs valeurs possibles.
Voici un exemple d'utilisation de l'opérateur IN dans une requête SELECT en MySQL :
SELECT *
FROM employees
WHERE department IN ('Sales', 'Marketing', 'Finance');
Dans cet exemple, la requête sélectionne tous les employés dont le département est soit "Sales", soit "Marketing", soit "Finance".
Il est important de noter que la liste de valeurs doit être encadrée par des parenthèses, et les valeurs doivent être séparées par des virgules. Il est également possible d'utiliser l'opérateur NOT IN pour sélectionner toutes les lignes dont la valeur de la colonne ne correspond pas à l'une des valeurs spécifiées.
Voici d'autres exemples de IN:
-- Liste fixe de valeurs
SELECT * FROM produits
WHERE categorie IN ('Électronique', 'Informatique', 'Téléphonie');
-- Avec des nombres
SELECT * FROM employes
WHERE departement_id IN (1, 3, 5);
-- Avec une sous-requête
SELECT * FROM clients
WHERE ville IN (
SELECT ville
FROM magasins
WHERE pays = 'France'
);
-- Combiné avec NOT pour exclure des valeurs
SELECT * FROM commandes
WHERE statut NOT IN ('annulée', 'en attente');
-- Avec des valeurs NULL (attention: NULL nécessite IS NULL)
SELECT * FROM contacts
WHERE telephone IN ('0123456789', '0987654321')
OR telephone IS NULL;
Note : IN est souvent plus lisible et plus efficace que plusieurs conditions OR
-- Ces deux requêtes sont équivalentes :
SELECT * FROM produits WHERE categorie IN ('A', 'B', 'C');
SELECT * FROM produits WHERE categorie = 'A' OR categorie = 'B' OR categorie = 'C';¶ IS NULL
L'opérateur IS NULL est utilisé dans MySQL pour vérifier si une valeur dans une colonne d'une table est nulle ou non. Il est souvent utilisé dans les requêtes SELECT pour filtrer les résultats en fonction de la présence ou de l'absence de valeurs nulles. La syntaxe de l'opérateur IS NULL est la suivante :
SELECT column_name
FROM table_name
WHERE column_name IS NULL;
Dans cet exemple, la requête SELECT retourne toutes les lignes de la table où la colonne spécifiée est nulle.
L'opérateur IS NULL est également utilisé dans les requêtes INSERT et UPDATE pour insérer ou mettre à jour une valeur nulle dans une colonne. Voici un exemple concret d'utilisation de l'opérateur IS NULL :
SELECT first_name, last_name, phone_number
FROM employees
WHERE phone_number IS NULL;
Dans cet exemple, la requête SELECT retourne toutes les lignes de la table des employés où la colonne "phone_number" est nulle.
Il est important de noter que l'opérateur IS NULL ne peut être utilisé que pour vérifier si une colonne est nulle ou non alors que = NULL est utilisé pour assigner une valeur à NULL.
-- Comparaison avec NULL (incorrect) -- NE PAS FAIRE: SELECT * FROM clients WHERE telephone = NULL -- FAIRE plutôt: SELECT * FROM clients WHERE telephone IS NULL
Voici d'autres exemple de IS NULL:
-- Trouver les clients sans adresse email
SELECT * FROM clients
WHERE email IS NULL;
-- Trouver les produits qui ont un prix défini
SELECT * FROM produits
WHERE prix IS NOT NULL;
-- Combiner avec d'autres conditions
SELECT * FROM employes
WHERE date_depart IS NULL
AND departement = 'Ventes';
-- Dans un UPDATE
UPDATE clients
SET telephone = '0123456789'
WHERE telephone IS NULL;¶ CASE
La commande CASE est une instruction de contrôle de flux dans MySQL qui permet d'effectuer différentes actions en fonction d'une condition. Elle est souvent utilisée dans les requêtes SELECT pour ajouter une colonne calculée ou pour afficher des données d'une manière spécifique en fonction des résultats de la condition. La syntaxe générale de l'instruction CASE est la suivante :
CASE
WHEN condition_1 THEN result_1
WHEN condition_2 THEN result_2
...
ELSE default_result
END
Dans cet exemple, chaque condition est évaluée dans l'ordre, et si une condition est vraie, la valeur correspondante est retournée. Si aucune condition n'est vraie, la valeur par défaut est retournée. Voici un exemple concret d'utilisation de l'instruction CASE :
SELECT first_name, last_name,
CASE
WHEN salary >= 50000 THEN 'Above Average'
WHEN salary >= 30000 THEN 'Average'
ELSE 'Below Average'
END AS salary_status
FROM employees;
Dans cet exemple, une colonne supplémentaire "salary_status" est ajoutée à la requête SELECT. Cette colonne affiche "Above Average" si le salaire est supérieur ou égal à 50000, "Average" si le salaire est compris entre 30000 et 49999, et "Below Average" si le salaire est inférieur à 30000.
¶ Fonctions scalaires
En SQL, une fonction scalaire est une fonction qui opère sur une seule valeur et retourne une seule valeur. MySQL propose plusieurs catégories de fonctions scalaires.
Fonctions de chaînes de caractères:
CONCAT('Hello', ' ', 'World') -- Résultat: "Hello World"
LENGTH('Bonjour') -- Résultat: 7
UPPER('texte') -- Résultat: "TEXTE"
LOWER('TEXTE') -- Résultat: "texte"
TRIM(' texte ') -- Supprime les espaces avant et après
SUBSTRING('Bonjour', 1, 3) -- Résultat: "Bon"Fonctions numériques:
ROUND(3.14159, 2) -- Résultat: 3.14
CEIL(3.1) -- Résultat: 4
FLOOR(3.9) -- Résultat: 3
ABS(-5) -- Résultat: 5
POWER(2, 3) -- Résultat: 8Fonctions de date et heures:
NOW() -- Date et heure actuelles
CURRENT_DATE() -- Date actuelle
DATE_FORMAT('2024-01-01', '%d/%m/%Y') -- Formatage de date
DATEDIFF('2024-01-01', '2023-12-31') -- Différence en jours
YEAR('2024-01-01') -- Extrait l'annéeFonctions de converstion:
CAST('123' AS SIGNED) -- Convertit en nombre
CONVERT('2024-01-01', DATE) -- Convertit en date
COALESCE(null, 'valeur2') -- Retourne la première valeur non nulleCes fonctions sont très utiles pour :
- Manipuler et formater les données
- Effectuer des calculs
- Gérer les dates
- Traiter les valeurs nulles
- Appliquer des conditions
¶ Fonctions de chaînes de caractères
Les "string functions" (ou "fonctions de chaînes de caractères" en français) sont des fonctions informatiques qui permettent de manipuler des chaînes de caractères (ou "strings" en anglais). Les chaînes de caractères sont des séquences de caractères qui peuvent être utilisées pour stocker du texte ou des données sous forme de texte.
Il existe de nombreuses fonctions de chaînes de caractères qui peuvent être utilisées pour effectuer différentes opérations sur des chaînes, telles que :
- La concaténation de chaînes (c'est-à-dire la fusion de deux ou plusieurs chaînes en une seule)
- La recherche d'un sous-ensemble de caractères dans une chaîne
- La substitution de certains caractères par d'autres dans une chaîne
- La conversion de chaînes en majuscules ou en minuscules
- La suppression de caractères ou de sous-chaînes d'une chaîne
- Le fractionnement d'une chaîne en sous-chaînes basées sur un délimiteur spécifié
- La détermination de la longueur d'une chaîne
Source: https://dev.mysql.com/doc/refman/8.0/en/string-functions.html
¶ CONCAT
La fonction CONCAT en SQL est une fonction de chaînes de caractères qui permet de concaténer (ou fusionner) deux ou plusieurs chaînes de caractères en une seule chaîne de caractères. La syntaxe générale de la fonction CONCAT est la suivante :
CONCAT(string1, string2, string3, ...)
La fonction CONCAT peut prendre un nombre variable d'arguments, ce qui signifie que vous pouvez fusionner plusieurs chaînes de caractères en une seule en spécifiant chaque chaîne de caractères séparés par une virgule en paramètre de la fonction. Voici des exemples:
-- Concaténer deux mots
SELECT CONCAT('Hello', ' World');
-- Résultat: 'Hello World'
-- Concaténer trois chaînes
SELECT CONCAT('Je', ' suis', ' Claude');
-- Résultat: 'Je suis Claude'
-- Concaténer avec des nombres
SELECT CONCAT('Numéro ', 42);
-- Résultat: 'Numéro 42'
-- Concaténer avec un espace
SELECT CONCAT('Bonjour', ' ', 'tout le monde');
-- Résultat: 'Bonjour tout le monde'
-- Concaténer avec des caractères spéciaux
SELECT CONCAT('Prix: ', 19.99, ' €');
-- Résultat: 'Prix: 19.99 €'
Il est important de noter que la fonction CONCAT peut également être utilisée avec des colonnes de base de données en SQL. Par exemple, si nous avons une table "personnes" avec les colonnes "nom" et "prenom", nous pouvons utiliser la fonction CONCAT pour fusionner les valeurs de ces colonnes en une seule chaîne de caractères :
SELECT CONCAT(nom, ' ', prenom) AS nom_complet FROM personnes;Ce qui renvoie une liste de noms complets fusionnant les colonnes nom et prénom de la table personnes.
¶ CONCAT_WS
La fonction CONCAT_WS est une fonction SQL qui permet de concaténer des chaînes de caractères en utilisant un délimiteur spécifique. Le "WS" dans CONCAT_WS signifie "With Separator" ou "Avec Séparateur" en français.
CONCAT_WS('delimiter', string1, string2, ...)où "delimiter" est le séparateur que vous souhaitez utiliser pour concaténer les chaînes de caractères, et "string1", "string2", ... sont les chaînes de caractères que vous souhaitez concaténer.
Supposons que vous souhaitiez concaténer les noms et les prénoms d'une table d'utilisateurs, en utilisant un espace comme séparateur. Vous pouvez utiliser la fonction CONCAT_WS comme suit :
-- Avec un espace comme séparateur
SELECT CONCAT_WS(' ', 'Hello', 'World', 'Today');
-- Résultat: 'Hello World Today'
-- Avec un tiret comme séparateur
SELECT CONCAT_WS('-', 'Jean', 'Pierre', 'Dupont');
-- Résultat: 'Jean-Pierre-Dupont'
-- Avec une virgule comme séparateur
SELECT CONCAT_WS(',', 'Paris', 'Lyon', 'Marseille');
-- Résultat: 'Paris,Lyon,Marseille'
-- Avec un point comme séparateur
SELECT CONCAT_WS('.', 'www', 'exemple', 'com');
-- Résultat: 'www.exemple.com'
-- Avec un slash comme séparateur
SELECT CONCAT_WS('/', '2024', '03', '15');
-- Résultat: '2024/03/15'
¶ SUBSTRING ou SUBSTR
La fonction SUBSTRING est une fonction SQL qui permet de récupérer une partie d'une chaîne de caractères. Elle est utilisée pour extraire une sous-chaîne d'une chaîne plus grande. La syntaxe de la fonction SUBSTRING est la suivante :
SUBSTRING(string, start, length)où "string" est la chaîne de caractères que vous souhaitez extraire, "start" est la position de départ de l'extraction et "length" est la longueur de la sous-chaîne à extraire. Voici un exemple:
Supposons que vous ayez une table d'utilisateurs contenant une colonne "email" et que vous souhaitiez extraire le nom d'utilisateur à partir de chaque adresse e-mail. Si toutes les adresses e-mail sont au format "nom_utilisateur@domaine.com", vous pouvez utiliser la fonction SUBSTRING pour extraire le nom d'utilisateur comme suit :
SELECT SUBSTRING(email, 1, CHARINDEX('@', email)-1) AS username FROM users;Cela renverra une colonne "username" qui contiendra le nom d'utilisateur pour chaque adresse e-mail dans la table.
Voici d'autres exemple de la fonction:
-- Extraire les premiers caractères
SELECT SUBSTRING('Bonjour le monde', 1, 7); -- Retourne 'Bonjour'
-- Extraire depuis une position jusqu'à la fin
SELECT SUBSTRING('contact@email.com', 8); -- Retourne 'email.com'
-- Extraire les derniers caractères (position négative)
SELECT SUBSTRING('12345', -3); -- Retourne '345'
-- Extraire une portion au milieu
SELECT SUBSTRING('abcdefghijk', 3, 4); -- Retourne 'cdef'
-- Avec un numéro de téléphone
SELECT SUBSTRING('0123456789', 1, 2) AS indicatif,
SUBSTRING('0123456789', 3, 2) AS zone,
SUBSTRING('0123456789', 5) AS numero;
-- Avec une date (format YYYY-MM-DD)
SELECT SUBSTRING('2024-03-15', 1, 4) AS annee,
SUBSTRING('2024-03-15', 6, 2) AS mois,
SUBSTRING('2024-03-15', 9, 2) AS jour;
-- Avec une adresse IP
SELECT SUBSTRING('192.168.1.1', 1,
LOCATE('.', '192.168.1.1')-1) AS premier_octet;
-- Code postal et ville
SELECT SUBSTRING('75001 PARIS', 1, 5) AS code_postal,
SUBSTRING('75001 PARIS', 7) AS ville;
-- Nettoyer une URL
SELECT SUBSTRING('https://www.example.com', 9) AS domaine;
-- Extraire le nom de domaine d'un email
SELECT SUBSTRING_INDEX('user@domain.com', '@', -1) AS domaine;¶ REPLACE
La fonction REPLACE() en SQL est utilisée pour remplacer toutes les occurrences d'une sous-chaîne dans une chaîne de caractères par une autre sous-chaîne. La syntaxe de la fonction REPLACE() est la suivante :
REPLACE(string, old_substring, new_substring)Où :
- string : est la chaîne de caractères dans laquelle vous voulez remplacer des sous-chaînes.
- old_substring : est la sous-chaîne que vous voulez remplacer.
- new_substring : est la nouvelle sous-chaîne que vous voulez utiliser pour remplacer la sous-chaîne précédente.
Par exemple, si vous avez une table appelée "employees" et que vous voulez remplacer tous les espaces dans la colonne "nom" par des tirets, vous pouvez utiliser la requête suivante :
SELECT REPLACE(nom, ' ', '-');Cette requête remplacera tous les espaces par des tirets dans la colonne "nom" de la table "employees".
Notez que la fonction REPLACE() est sensible à la casse, ce qui signifie que si vous cherchez à remplacer la sous-chaîne 'a' par la sous-chaîne 'A', seuls les 'a' en minuscules seront remplacés.
Voici des exemples de la fonction:
-- Remplacement simple
SELECT REPLACE('Bonjour le monde', 'monde', 'world');
-- Résultat: 'Bonjour le world'
-- Remplacer plusieurs occurrences
SELECT REPLACE('hello hello hello', 'hello', 'hi');
-- Résultat: 'hi hi hi'
-- Dans une adresse email
SELECT REPLACE('contact@anciendomaine.com', '@anciendomaine.com', '@nouveaudomaine.com');
-- Résultat: 'contact@nouveaudomaine.com'
-- Supprimer des caractères
SELECT REPLACE('123-456-789', '-', '');
-- Résultat: '123456789'
-- Nettoyer des espaces multiples
SELECT REPLACE('texte avec espaces', ' ', ' ');
-- Résultat: 'texte avec espaces'
-- Formater un numéro de téléphone
SELECT REPLACE('0123456789', '0', '+33');
-- Résultat: '+33123456789'
-- Corriger des fautes courantes
SELECT REPLACE('developper', 'pp', 'p');
-- Résultat: 'developer'
-- Dans une requête UPDATE
UPDATE utilisateurs
SET email = REPLACE(email, '@old.com', '@new.com');
-- Remplacements multiples (chaînés)
SELECT REPLACE(
REPLACE(
REPLACE('Hello World!', 'Hello', 'Bonjour'),
'World', 'Monde'
),
'!', ' !'
);
-- Nettoyer des URLs
SELECT REPLACE('www.example.com', 'www.', '');
-- Résultat: 'example.com'¶ REVERSE
La fonction REVERSE() en SQL est utilisée pour inverser l'ordre des caractères d'une chaîne de caractères.
REVERSE(string);où "string" est la chaîne de caractères à inverser.
Par exemple, si vous avez la chaîne de caractères "Bonjour", la fonction REVERSE() la renverra comme "ruojnoB".
Voici des exemples d'utilisation de la fonction REVERSE() en SQL :
-- Inverser un mot simple
SELECT REVERSE('bonjour');
-- Résultat: 'ruojnob'
-- Inverser une phrase
SELECT REVERSE('Hello World');
-- Résultat: 'dlroW olleH'
-- Vérifier si un mot est un palindrome
SELECT mot,
IF(mot = REVERSE(mot), 'Palindrome', 'Non palindrome') AS est_palindrome
FROM (SELECT 'radar' AS mot) AS t;
-- Inverser des nombres
SELECT REVERSE('12345');
-- Résultat: '54321'
-- Inverser un email
SELECT REVERSE('user@domaine.com');
-- Résultat: 'moc.eniamod@resu'
-- Combiner avec d'autres fonctions
SELECT CONCAT(
REVERSE('ABC'),
'-',
'XYZ'
);
-- Résultat: 'CBA-XYZ'La fonction REVERSE() peut être utilisée dans les clauses SELECT, WHERE et ORDER BY, entre autres.
¶ CHAR_LENGTH
La fonction CHAR_LENGTH() en SQL est utilisée pour obtenir la longueur d'une chaîne de caractères. La syntaxe de cette fonction est la suivante :
CHAR_LENGTH(string)où "string" est la chaîne de caractères dont vous voulez obtenir la longueur.
Par exemple, si vous avez la chaîne de caractères "Bonjour", la fonction CHAR_LENGTH() renverra 7 car il y a 7 caractères dans cette chaîne.
SELECT CHAR_LENGTH('Bonjour') AS string_length;La fonction CHAR_LENGTH() peut être utilisée dans les clauses SELECT, WHERE et ORDER BY, entre autres. Elle est utile pour effectuer des opérations sur des chaînes de caractères, telles que la comparaison ou l'extraction d'une partie d'une chaîne.
Ne pas confondre la fonction CHAR_LENGTH avec la fonction LENGTH, surtout avec les caractères spéciaux (ex.: ©≠Ω¥Ù)
La fonction LENGHT retourne la valeur en bytes!
¶ UPPER (UCASE) et LOWER (LCASE)
La fonction UPPER et la fonction LOWER sont des fonctions de chaîne de caractères en SQL qui permettent de convertir une chaîne de caractères en majuscules ou en minuscules, respectivement.
La fonction LOWER, quant à elle, convertit toutes les lettres d'une chaîne de caractères en minuscules. Par exemple, si vous avez une chaîne de caractères "Bonjour", la fonction LOWER renverra "bonjour". La syntaxe de la fonction LOWER en SQL est la suivante :
SELECT LOWER(nom_de_la_colonne) FROM nom_de_la_table;
La fonction UPPER convertit toutes les lettres d'une chaîne de caractères en majuscules. Par exemple, si vous avez une chaîne de caractères "Bonjour", la fonction UPPER renverra "BONJOUR".
SELECT UPPER(nom_de_la_colonne) FROM nom_de_la_table;
Ces fonctions sont utiles lorsqu'il est nécessaire de comparer des chaînes de caractères sans tenir compte de la casse (majuscules ou minuscules).
Voici des exemples pour chacunes des fonctions:
-- Conversion simple en majuscules
SELECT UPPER('hello world');
-- Résultat: 'HELLO WORLD'
-- Conversion simple en minuscules
SELECT LOWER('HELLO WORLD');
-- Résultat: 'hello world'
-- Combinaison des deux
SELECT LOWER(email), UPPER(nom)
FROM utilisateurs;
-- Première lettre en majuscule, reste en minuscule
SELECT CONCAT(
UPPER(SUBSTRING(prenom, 1, 1)),
LOWER(SUBSTRING(prenom, 2))
);
-- Standardisation d'emails
SELECT LOWER('Contact@EMAIL.com');
-- Résultat: 'contact@email.com'
-- Dans une condition WHERE (insensible à la casse)
SELECT * FROM utilisateurs
WHERE LOWER(statut) = 'actif';
-- Formater un nom
SELECT
UPPER(nom) as NOM,
LOWER(prenom) as prenom;
-- Dans un UPDATE
UPDATE clients
SET email = LOWER(email);
-- Vérification insensible à la casse
SELECT * FROM produits
WHERE LOWER(categorie) = 'électronique';
-- Combinaison avec REPLACE
SELECT UPPER(
REPLACE(titre, ' ', '_')
) AS format_special;¶ INSERT
La fonction INSERT(str, pos, len, newstr) est une fonction de chaîne de caractères en SQL qui permet d'insérer une nouvelle sous-chaîne dans une chaîne de caractères existants.
SELECT INSERT(str,pos,len,newstr);•str : La chaîne de caractères à modifier.
•pos : La position à laquelle la nouvelle sous-chaîne doit être insérée dans str.
•len : La longueur de la sous-chaîne à remplacer.
•newstr : La nouvelle sous-chaîne à insérer dans str.
La fonction va prendre la chaîne de caractères spécifiés dans str et insérer la sous-chaîne newstr à la position pos, en remplaçant len caractères. La fonction INSERT peut donc remplacer ou rajouter des caractères.
Voici des exemples de la fonction:
-- Insertion simple
SELECT INSERT('Bonjour', 4, 0, ' tout');
-- Résultat: 'Bon tout jour'
-- Remplacer des caractères
SELECT INSERT('MySQL SQL', 6, 3, 'est');
-- Résultat: 'MySQL est'
-- Dans un numéro de téléphone
SELECT INSERT('0123456789', 1, 1, '+33');
-- Résultat: '+33123456789'
-- Remplacer au milieu
SELECT INSERT('abcdefgh', 3, 2, 'XXX');
-- Résultat: 'abXXXefgh'
-- Ne rien remplacer (len=0)
SELECT INSERT('texte', 1, 0, 'Mon ');
-- Résultat: 'Mon texte'
-- Remplacer à la fin
SELECT INSERT('Hello', 6, 0, ' World');
-- Résultat: 'Hello World'
-- Avec des adresses email
SELECT INSERT('user@old.com', 5, 7, '@new');
-- Résultat: 'user@new.com'
-- Multiple insertions (imbriquées)
SELECT INSERT(
INSERT('ABC123', 4, 3, 'XYZ'),
1, 1, '0'
);
-- Résultat: '0BCXYZ'¶ Autres fonctions
L’ensemble des fonctions sur les chaînes de caractères sont décrites sur le site de MySQL:
https://dev.mysql.com/doc/refman/8.0/en/string-functions.html
Vous devriez être en mesure de lire et comprendre ces fonctions par vous-même:
- LEFT
- RIGHT
- REPEAT
- TRIM
¶ DATE et TIME
Pour en savoir plus sur les fonctions de date et heure: https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html
¶ CURRENT
CURDATE() retourne la date actuelle sous forme de chaîne de caractères au format 'AAAA-MM-JJ'. Cette fonction ne prend pas d'argument.
CURTIME() retourne l'heure actuelle sous forme de chaîne de caractères au format 'HH:MM:SS'. Cette fonction ne prend pas d'argument.
NOW() retourne la date et l'heure actuelles sous forme de date et heure combinées. Cette fonction ne prend pas d'argument.
########################
# CURDATE, CURTIME et NOW
########################
-- Obtenir l'heure actuelle
SELECT CURTIME();
-- Obtenir la date actuelle
SELECT CURDATE();
-- Obtenir la date et l'heure actuelles
SELECT NOW();
-- Exemple d'insertion avec ces fonctions
INSERT INTO people (name, birthdate, birthtime, birthdt)
VALUES ('Hazel', CURDATE(), CURTIME(), NOW());¶ Fonction DATE
DATE(): Cette fonction est utilisée pour extraire la partie de la date à partir d'une expression de date. Elle prend une expression de date en argument et renvoie la date uniquement sous forme AAAA-MM-JJ.
SELECT DATE('2023-05-06 15:30:45');
- Résultat: 2023-05-06
YEAR(): Cette fonction est utilisée pour extraire l'année à partir d'une expression de date. Elle prend une expression de date en argument et renvoie l'année sous forme AAAA.
SELECT YEAR('2023-05-06');
- Résultat: 2023
MONTH(): Cette fonction est utilisée pour extraire le mois à partir d'une expression de date. Elle prend une expression de date en argument et renvoie le mois sous forme MM.
SELECT MONTH('2023-05-06');
- Résultat: 05
DAY(): Cette fonction est utilisée pour extraire le jour à partir d'une expression de date. Elle prend une expression de date en argument et renvoie le jour sous forme JJ.
SELECT DAY('2023-05-06');
- Résultat: 06
DATE_FORMAT(): Cette fonction est utilisée pour formater une expression de date selon un format spécifié. Elle prend deux arguments: l'expression de date et le format de date.
SELECT DATE_FORMAT('2023-05-06 15:30:45', '%W %M %Y');
- Résultat: Friday May 2023
ADDDATE(): Cette fonction est utilisée pour ajouter une période de temps spécifiée à une date. Elle prend deux arguments: la date d'origine et la période à ajouter.
SELECT ADDDATE('2023-05-06', INTERVAL 1 MONTH);
- Résultat: 2023-06-06
Autres fonctions intéressantes:
- DAYOFWEEK()
- DAYOFYEAR()
- MONTHNAME()
¶ Fonction TIME
TIME(): Cette fonction est utilisée pour extraire la partie temps d'une expression de date ou de temps. Elle prend une expression de date ou de temps en argument et renvoie le temps uniquement sous forme HH:MM:SS.
SELECT TIME('2023-05-06 15:30:45');
- Résultat: 15:30:45
HOUR(): Cette fonction est utilisée pour extraire l'heure d'une expression de temps. Elle prend une expression de temps en argument et renvoie l'heure sous forme HH.
SELECT HOUR('15:30:45');
- Résultat: 15
MINUTE(): Cette fonction est utilisée pour extraire les minutes d'une expression de temps. Elle prend une expression de temps en argument et renvoie les minutes sous forme MM.
SELECT MINUTE('15:30:45');
- Résultat: 30
SECOND(): Cette fonction est utilisée pour extraire les secondes d'une expression de temps. Elle prend une expression de temps en argument et renvoie les secondes sous forme SS.
SELECT SECOND('15:30:45');
- Résultat: 45
TIMEDIFF(): Cette fonction est utilisée pour calculer la différence entre deux expressions de temps. Elle prend deux expressions de temps en argument et renvoie la différence sous forme d'un intervalle de temps.
SELECT TIMEDIFF('15:30:45', '12:45:30');
- Résultat: 02:45:15
ADDTIME(): Cette fonction est utilisée pour ajouter une période de temps spécifiée à une expression de temps. Elle prend deux arguments: l'expression de temps et la période à ajouter.
SELECT ADDTIME('15:30:45', '02:15:00');
- Résultat: 17:45:45
¶ DATE_FORMAT
La fonction DATE_FORMAT est utilisée pour formater les valeurs de date et d'heure en une chaîne de caractères selon un format spécifié. Le format de la chaîne de sortie est déterminé par les spécificateurs de format qui sont placés dans la chaîne de format. La syntaxe de la fonction DATE_FORMAT est la suivante:
DATE_FORMAT(date, format)où date est la valeur de date ou d'heure à formater, et format est la chaîne de format spécifiant le format de sortie. Voici quelques exemples de chaînes de format courants pour DATE_FORMAT:
- %Y: année, format à quatre chiffres
- %y: année, format à deux chiffres
- %m: mois (01 à 12)
- %b: mois, abrégé (jan, fév, mar, etc.)
- %d: jour du mois (01 à 31)
- %a: nom abrégé du jour de la semaine (dim, lun, mar, etc.)
- %W: nom complet du jour de la semaine (dimanche, lundi, mardi, etc.)
- %H: heure, format 24 heures (00 à 23)
- %h: heure, format 12 heures (01 à 12)
- %i: minutes (00 à 59)
- %s: secondes (00 à 59)
- %p: AM ou PM en majuscules
Exemple:
SELECT DATE_FORMAT('2023-05-06', '%Y-%m-%d');
- Résultat: 2023-05-06
¶ DATE MATH
DATEDIFF(): Est utilisée pour calculer la différence entre deux dates en jours, mois ou années. Voici la syntaxe générale de cette fonction:
DATEDIFF(date1, date2);Où:
- date1 et date2 sont les dates entre lesquelles calculer la différence.
La fonction renvoie un entier représentant la différence entre les deux dates en nombre de jours. Si date1 est antérieur à date2, le résultat sera positif. Si date1 est postérieur à date2, le résultat sera négatif.
Plus d'info à: https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_date-add
DATE_ADD() ou DATA_SUB(): Est utilisée pour ajouter/retirer une durée à une date ou une date/heure spécifiée. La syntaxe générale est la suivante :
DATE_ADD(date, INTERVAL expr unit);
DATE_SUB(date, INTERVAL expr unit);
où :
- date est la date/heure à laquelle vous voulez ajouter une durée ;
- INTERVAL est un mot-clé qui doit être utilisé avant la durée que vous souhaitez ajouter ;
- expr est la durée que vous voulez ajouter à la date/heure spécifiée. Cette durée doit être une expression entière ou décimale ;
- unit est l'unité de temps pour la durée que vous voulez ajouter, telle que YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, etc.
Plus d'info à: https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_date-sub
¶ Fonctions d'aggrégation
¶ Script
Create database Meslivres;
use Meslivres;
CREATE TABLE books
(
book_id INT AUTO_INCREMENT,
title VARCHAR(100),
author_fname VARCHAR(100),
author_lname VARCHAR(100),
released_year INT,
stock_quantity INT,
pages INT,
PRIMARY KEY(book_id)
);
INSERT INTO books (title, author_fname, author_lname, released_year, stock_quantity, pages)
VALUES
('The Namesake', 'Jhumpa', 'Lahiri', 2003, 32, 291),
('Norse Mythology', 'Neil', 'Gaiman',2016, 43, 304),
('American Gods', 'Neil', 'Gaiman', 2001, 12, 465),
('Interpreter of Maladies', 'Jhumpa', 'Lahiri', 1996, 97, 198),
('A Hologram for the King: A Novel', 'Dave', 'Eggers', 2012, 154, 352),
('The Circle', 'Dave', 'Eggers', 2013, 26, 504),
('The Amazing Adventures of Kavalier & Clay', 'Michael', 'Chabon', 2000, 68, 634),
('Just Kids', 'Patti', 'Smith', 2010, 55, 304),
('A Heartbreaking Work of Staggering Genius', 'Dave', 'Eggers', 2001, 104, 437),
('Coraline', 'Neil', 'Gaiman', 2003, 100, 208),
('What We Talk About When We Talk About Love: Stories', 'Raymond', 'Carver', 1981, 23, 176),
("Where I'm Calling From: Selected Stories", 'Raymond', 'Carver', 1989, 12, 526),
('White Noise', 'Don', 'DeLillo', 1985, 49, 320),
('Cannery Row', 'John', 'Steinbeck', 1945, 95, 181),
('Oblivion: Stories', 'David', NULL, 2004, 172, 329),
('Consider the Lobster', NULL, 'Foster Wallace', 2005, 92, 343),
('10% Happier', 'Dan', 'Harris', NULL, 29, 256),
('fake_book', 'Freida', 'Harris', 2001, NULL, 428),
('Lincoln In The Bardo', 'George', 'Saunders', 2017, 1000, NULL);
# ***********************************************
# Règles fondamentales
# ***********************************************
/* Règle 1: Toute colonne dans le SELECT qui n'est pas dans une fonction d'agrégation DOIT apparaître dans le GROUP BY.
Règle 2: Vous pouvez grouper par plusieurs colonnes
Règle 3: GROUP BY est souvent utilisé avec HAVING (qui est comme un WHERE pour les groupes)
Règle 1
SELECT colonne A, sum(colonne C) from tablex
GROUP BY colonne A
car sinon erreur sans le GORUP BY
SELECT colonne A, sum(colonne C) from tablex => ERREUR!
SELECT sum(colonne A), sum(colonne C) from tablex => Ok car aucuen colonne n'est laissé seule
Règle 2
SELECT colonne A, colonne B, sum(colonne C) from tablex
GROUP BY colonne A, colonne B
Règle 3
SELECT colonne A, colonne B, sum(colonne C) from tablex
GROUP BY colonne A, colonne B
HAVING sum(colonne C) > 150
*/
# ***********************************************
# COUNT
# ***********************************************
#Attention à l'auteur avec une valeur NULLE!
SELECT COUNT(author_fname) FROM books;
SELECT COUNT(*) FROM books WHERE pages > 400;
SELECT author_fname, count(title) FROM books
GROUP BY author_fname;
SELECT COUNT(*) FROM books;
# ***********************************************
# SUM
# ***********************************************
SELECT SUM(pages) as total_pages FROM books;
# Erreur sans le GROUP BY
SELECT author_fname,SUM(stock_quantity) as total_stock
FROM books;
#OK avec le GROUP BY
SELECT author_fname,SUM(stock_quantity) as total_stock
FROM books
GROUP BY author_fname;
#OK si aucune colonne n'est laissé seule
SELECT SUM(author_fname),SUM(stock_quantity) as total_stock
FROM books;
# ***********************************************
# AVG
# ***********************************************
#Erreur sans le GROUP BY!
SELECT author_fname, AVG(pages) as moyenne_pages
FROM books;
SELECT author_fname, AVG(pages) as moyenne_pages
FROM books
GROUP BY author_fname;
# ***********************************************
# MIN et MAX
# ***********************************************
SELECT MIN(pages) from books;
SELECT MAX(released_year) from books;
# ***********************************************
# GROUP BY
# ***********************************************
#Cette requête regroupe tous les livres par nom de famille d'auteur
# et compte combien de livres chaque auteur a écrit.
SELECT author_lname, COUNT(*) as nombre_livres
FROM books
GROUP BY author_lname;
-- Calculer le nombre total de livres en stock par auteur
SELECT
author_fname,
author_lname,
SUM(stock_quantity) as total_stock
FROM books
WHERE stock_quantity IS NOT NULL
GROUP BY author_fname, author_lname
ORDER BY total_stock DESC;
-- Calculer le nombre total de livres en stock par année de publication
SELECT
released_year,
SUM(stock_quantity) as total_stock_par_annee
FROM books
WHERE released_year IS NOT NULL
AND stock_quantity IS NOT NULL
GROUP BY released_year
ORDER BY released_year DESC;
# ***********************************************
# HAVING
# ***********************************************
-- Trouver les auteurs qui ont écrit plus de 2 livres
SELECT
author_fname,
author_lname,
COUNT(*) as nombre_livres
FROM books
WHERE author_fname IS NOT NULL
GROUP BY author_fname, author_lname
HAVING nombre_livres > 2;
-- Trouver les années où le stock total est supérieur à 100 exemplaires
SELECT
released_year,
SUM(stock_quantity) as stock_total
FROM books
WHERE released_year IS NOT NULL
AND stock_quantity IS NOT NULL
GROUP BY released_year
HAVING stock_total > 100
ORDER BY stock_total DESC;
-- Trouver les années où la moyenne des pages des livres est supérieure à 300
SELECT
released_year,
COUNT(*) as nombre_livres,
ROUND(AVG(pages), 0) as moyenne_pages
FROM books
WHERE released_year IS NOT NULL
AND pages IS NOT NULL
GROUP BY released_year
HAVING moyenne_pages > 300
ORDER BY moyenne_pages DESC;¶ Introduction
En SQL, l'agrégation est un concept qui consiste à effectuer des calculs sur des ensembles de données pour obtenir des résultats agrégés (ou synthétiques) à partir de multiples enregistrements. Cela permet de traiter des données sur un niveau plus élevé, en fournissant des informations plus générales et résumées.
L'agrégation en SQL est généralement utilisée en combinaison avec la clause GROUP BY, qui divise les enregistrements en groupes en fonction de la valeur d'une ou plusieurs colonnes. Les fonctions d'agrégation sont ensuite appliquées à chaque groupe pour calculer les valeurs agrégées.
Il existe plusieurs fonctions d'agrégation couramment utilisées en SQL, notamment :
- COUNT : calcule le nombre d'enregistrements dans un groupe.
- SUM : calcule la somme des valeurs dans un groupe.
- AVG : calcule la moyenne des valeurs dans un groupe.
- MAX : retourne la valeur maximale dans un groupe.
- MIN : retourne la valeur minimale dans un groupe.
Voici des exemples :
-- COUNT : Compte le nombre de lignes ou de valeurs non NULL
SELECT COUNT(*) FROM employes;
SELECT COUNT(DISTINCT departement) FROM employes;
-- SUM : Calcule la somme des valeurs
SELECT SUM(salaire) FROM employes;
SELECT SUM(quantite * prix) FROM commandes;
-- AVG : Calcule la moyenne
SELECT AVG(age) FROM etudiants;
SELECT AVG(NULLIF(note, 0)) FROM examens; -- ignore les zéros
-- MAX et MIN : Trouve la valeur maximale et minimale
SELECT MAX(prix) FROM produits;
SELECT MIN(date_commande) FROM commandes;
-- GROUP BY : Regroupe les résultats pour les fonctions d'agrégation
SELECT departement, COUNT(*), AVG(salaire)
FROM employes
GROUP BY departement;
-- HAVING : Filtre sur les résultats agrégés (comme WHERE mais pour les groupes)
SELECT categorie, AVG(prix)
FROM produits
GROUP BY categorie
HAVING AVG(prix) > 100;
-- Combinaisons complexes
SELECT
departement,
COUNT(*) as nb_employes,
MAX(salaire) as salaire_max,
MIN(salaire) as salaire_min,
AVG(salaire) as salaire_moyen
FROM employes
WHERE date_depart IS NULL
GROUP BY departement
HAVING COUNT(*) > 5
ORDER BY salaire_moyen DESC;
Pour plus d'information sur les fonctions d'agréagation: https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html
¶ GROUP BY
La clause GROUP BY en SQL est utilisée pour regrouper les résultats d'une requête en fonction de la valeur d'une ou plusieurs colonnes. Cela permet d'effectuer des opérations d'agrégation sur les données regroupées, telles que le calcul de la somme, de la moyenne, du maximum ou du minimum pour chaque groupe. La syntaxe est la suivante:
SELECT colonne1, colonne2, ..., colonneN, fonction_agregation(colonne)
FROM table
GROUP BY colonne1, colonne2, ..., colonneN;
#Une autre façon de le schématiser
SELECT colonne_a_grouper, fonction_agregation()
FROM table
GROUP BY colonne_a_grouper;Dans cette syntaxe, "colonne1, colonne2, ..., colonneN" sont les colonnes de la table que vous souhaitez regrouper, et "fonction_agrégation(colonne)" est la fonction d'agrégation que vous souhaitez utiliser pour chaque groupe (ex.: COUNT) .
Voici des exemples:
# Calculer la moyenne des notes par cours
SELECT cours, AVG(note) as moyenne_notes
FROM notes
GROUP BY cours;
#Compter le nombre d'utilisateur par pays
SELECT pays, COUNT(*) as nombre_utilisateurs
FROM utilisateurs
GROUP BY pays;Voici un visualisation du GROUP BY

¶ GROUP BY avec plusieurs colonnes
Lorsque vous souhaitez utiliser plusieurs colonnes pour regrouper les enregistrements, vous pouvez simplement spécifier ces colonnes dans la clause "GROUP BY", en les séparant par des virgules. Voici un exemple pour mieux comprendre. Supposons que nous avons une table "ventes" avec les colonnes "pays", "ville", "produit" et "montant". Si nous voulons regrouper les ventes par pays et ville, nous pouvons utiliser la clause "GROUP BY" de cette manière :
SELECT pays, ville, SUM(montant) as total_ventes
FROM ventes
GROUP BY pays, ville;Dans cette requête, nous spécifions deux colonnes dans la clause "GROUP BY" : "pays" et "ville". Cela signifie que les enregistrements de la table "ventes" seront regroupés en fonction des valeurs de ces deux colonnes. Ensuite, nous utilisons la fonction d'agrégation "SUM" pour calculer le total des ventes pour chaque groupe, en utilisant la colonne "montant". Nous renommons cette colonne agrégée en "total_ventes" à l'aide de l'alias "as".
Le résultat de cette requête sera une table qui regroupe les enregistrements de la table "ventes" par pays et ville, et affiche le total des ventes pour chaque groupe.
Points importants à comprendre sur GROUP BY :
- Règle 1: Toute colonne dans le SELECT qui n'est pas dans une fonction d'agrégation DOIT apparaître dans le GROUP BY.
- Règle 2: Vous pouvez grouper par plusieurs colonnes
- Règle 3: GROUP BY est souvent utilisé avec HAVING (qui est comme un WHERE pour les groupes)
- Règle 1
SELECT colonne A, sum(colonne C) from tableX
GROUP BY colonne A
- Règle 2
SELECT colonne A, colonne B, sum(colonne C) from tableX
GROUP BY colonne A, colonne B
- Règle 3
SELECT colonne A, colonne B, sum(colonne C) from tableX
GROUP BY colonne A, colonne B
HAVING sum(colonne C) > 150
Si les règles fondamentales ne sont pas respectées, vous risqez d'avoir l'erreur suivante:

¶ HAVING
HAVING est une clause SQL qui permet de filtrer les résultats de groupes créés par GROUP BY, en appliquant des conditions sur les fonctions d'agrégation.
Voici des exemples:
-- Trouver les départements ayant plus de 5 employés
SELECT departement, COUNT(*) as nb_employes
FROM employes
GROUP BY departement
HAVING COUNT(*) > 5;
-- Catégories de produits dont la moyenne des prix dépasse 100€
SELECT categorie, AVG(prix) as prix_moyen
FROM produits
GROUP BY categorie
HAVING AVG(prix) > 100;
-- Clients ayant dépensé plus de 1000€ au total
SELECT client_id, SUM(montant) as total_achats
FROM commandes
GROUP BY client_id
HAVING SUM(montant) > 1000;
-- Combinaison de WHERE et HAVING
SELECT ville, COUNT(*) as nb_clients
FROM clients
WHERE pays = 'France'
GROUP BY ville
HAVING COUNT(*) > 10;
-- HAVING avec plusieurs conditions
SELECT categorie, AVG(prix) as prix_moyen, COUNT(*) as nb_produits
FROM produits
GROUP BY categorie
HAVING AVG(prix) > 50 AND COUNT(*) >= 3;
Points importants :
- WHERE filtre les lignes avant le groupement
- HAVING filtre les groupes après le groupement
- HAVING s'utilise toujours avec GROUP BY
- HAVING peut utiliser des fonctions d'agrégation (COUNT, SUM, AVG, etc.)
Voici une vidéo explicative de GROUP BY avec HAVING
¶ COUNT
COUNT est une fonction d'agrégation de base en SQL qui permet de compter le nombre de lignes ou d'enregistrements dans une table ou dans un groupe de résultats. La syntaxe générale pour utiliser COUNT est la suivante :
SELECT COUNT(colonne) FROM table;
#Attention au cas de figure ci-dessous
COUNT(*) -- compte toutes les lignes
COUNT(colonne) -- compte les valeurs non NULLCette requête renvoie le nombre total d'enregistrements dans la table spécifiée. Vous pouvez également utiliser la fonction COUNT avec la clause WHERE pour compter les enregistrements qui répondent à certaines conditions. Par exemple :
SELECT COUNT(*) FROM table WHERE colonne = 'valeur';Cela renvoie le nombre total d'enregistrements dans la table qui ont la valeur spécifiée dans la colonne spécifiée. Vous pouvez également utiliser COUNT avec la clause GROUP BY pour obtenir des résultats agrégés pour chaque groupe. Par exemple :
SELECT categorie, COUNT(*) FROM produits GROUP BY categorie;Cette requête renvoie le nombre total de produits dans chaque catégorie de produits. La clause GROUP BY divise les résultats en groupes en fonction de la valeur de la colonne "categorie", puis la fonction COUNT calcule le nombre total de produits dans chaque groupe.
Lorsque vous utilisez la fonction COUNT avec une colonne spécifique, la fonction COUNT ne comptera que les enregistrements qui ont une valeur non nulle pour cette colonne spécifique. Par exemple, si vous avez une table "clients" avec une colonne "adresse_email", et que vous souhaitez compter le nombre total de clients qui ont une adresse e-mail, vous pouvez utiliser la fonction COUNT de la manière suivante :
SELECT COUNT(adresse_email) FROM clients;Cette requête renverra le nombre total de clients qui ont une adresse e-mail renseignée. Les enregistrements qui ont une valeur nulle dans la colonne "adresse_email" ne seront pas comptabilisés.
En revanche, si vous utilisez l'opérateur "*" avec la fonction COUNT, elle comptera tous les enregistrements, y compris ceux qui ont des valeurs nulles dans certaines colonnes. Par exemple, si vous souhaitez compter le nombre total de clients dans la table "clients", vous pouvez utiliser la fonction COUNT de la manière suivante :
SELECT COUNT(*) FROM clients;Cette requête renverra le nombre total de clients, y compris ceux qui ont une valeur nulle dans la colonne "adresse_email".
¶ SUM
La fonction SUM en SQL est une fonction d'agrégation qui permet de calculer la somme des valeurs d'une colonne numérique pour un ensemble d'enregistrements dans une table. La syntaxe générale de la fonction SUM est la suivante :
SUM(colonne);Où "colonne" est le nom de la colonne numérique pour laquelle vous souhaitez calculer la somme.
Par exemple:
SELECT produit, SUM(montant) as total_ventes
FROM ventes
GROUP BY produit;Dans cette requête, nous utilisons la fonction SUM pour calculer la somme des montants de vente pour chaque produit dans la table "ventes". Nous renommons cette colonne agrégée en "total_ventes" à l'aide de l'alias "as". Ensuite, nous utilisons la clause "GROUP BY" pour regrouper les enregistrements de la table "ventes" par produit.
Le résultat de cette requête sera une table qui regroupe les enregistrements de la table "ventes" par produit, et affiche la somme des ventes pour chaque groupe.
Voiic d'autres exemple de l'utilisation de SUM:
-- Simple somme d'une colonne
SELECT SUM(montant) FROM ventes;
-- Somme avec condition WHERE
SELECT SUM(prix)
FROM produits
WHERE categorie = 'Électronique';
-- Somme avec calcul
SELECT SUM(prix * quantite) as chiffre_affaires
FROM commandes;
-- Somme par groupe (avec GROUP BY)
SELECT categorie, SUM(montant) as total_ventes
FROM ventes
GROUP BY categorie;
-- Somme conditionnelle avec CASE
SELECT SUM(
CASE
WHEN type_paiement = 'carte' THEN montant
ELSE 0
END
) as total_paiements_carte
FROM transactions;
-- Plusieurs SUM dans une même requête
SELECT
SUM(salaire) as masse_salariale,
SUM(bonus) as total_bonus,
SUM(salaire + bonus) as total_remuneration
FROM employes;
N'oubliez pas que SUM :
- Ignore les valeurs NULL
- Ne fonctionne qu'avec des valeurs numériques
- Peut être combiné avec d'autres fonctions d'agrégation
¶ AVERAGE
La fonction AVG en SQL est une fonction d'agrégation qui permet de calculer la moyenne arithmétique des valeurs d'une colonne numérique pour un ensemble d'enregistrements dans une table. La syntaxe générale de la fonction AVG est la suivante :
AVG(colonne);Où "colonne" est le nom de la colonne numérique pour laquelle vous souhaitez calculer la moyenne.
Exemple:
SELECT eleve, AVG(note) as moyenne_notes
FROM notes
GROUP BY eleve;Dans cette requête, nous utilisons la fonction AVG pour calculer la moyenne des notes pour chaque élève dans la table "notes". Nous renommons cette colonne agrégée en "moyenne_notes" à l'aide de l'alias "as". Ensuite, nous utilisons la clause "GROUP BY" pour regrouper les enregistrements de la table "notes" par élève.
Le résultat de cette requête sera une table qui regroupe les enregistrements de la table "notes" par élève, et affiche la moyenne des notes pour chaque groupe.
Voici d'autres exemples de la fonction AVG:
-- Moyenne simple d'une colonne
SELECT AVG(salaire) FROM employes;
-- Moyenne avec condition
SELECT AVG(prix)
FROM produits
WHERE categorie = 'Informatique';
-- Moyenne par groupe
SELECT departement, AVG(salaire) as salaire_moyen
FROM employes
GROUP BY departement;
-- Moyenne en ignorant les valeurs nulles
SELECT AVG(NULLIF(note, 0)) as moyenne_notes
FROM examens;
-- Moyenne avec arrondi
SELECT ROUND(AVG(prix), 2) as prix_moyen
FROM produits;
-- Plusieurs moyennes dans une même requête
SELECT
categorie,
AVG(prix) as prix_moyen,
AVG(quantite) as quantite_moyenne,
AVG(prix * quantite) as valeur_moyenne_stock
FROM produits
GROUP BY categorie;
Points importants à retenir :
- AVG ignore automatiquement les valeurs NULL
- Elle ne fonctionne qu'avec des valeurs numériques
- On peut l'arrondir avec ROUND
- Souvent utilisée avec GROUP BY pour des moyennes par groupe
¶ Min et MAX
Les fonctions "MIN" et "MAX" sont des fonctions d'agrégation en SQL qui permettent de retourner la valeur minimale et maximale d'une colonne spécifique dans une table.
La fonction "MIN" retourne la valeur minimale d'une colonne donnée, tandis que la fonction "MAX" retourne la valeur maximale de la même colonne. Ces fonctions peuvent être appliquées à n'importe quelle colonne numérique ou de texte qui contient des valeurs comparables. La syntaxe est la suivante:
SELECT MIN(colonne) FROM table;
SELECT MAX(colonne) FROM table;
#Exemple
SELECT MIN(prix) AS prix_minimum, MAX(prix) AS prix_maximum FROM produits;Cette requête renverra les valeurs minimale et maximale de la colonne "prix" de la table "produits". Les résultats seront renvoyés sous forme de deux colonnes distinctes : "prix_minimum" et "prix_maximum"
¶ Contraintes
¶ Script
##############################
#UNIQUE
##############################
use meslivres;
CREATE TABLE contacts (
name VARCHAR(100) NOT NULL,
phone VARCHAR(15) NOT NULL UNIQUE
);
INSERT INTO contacts (name, phone)
VALUES ('billybob', '8781213455');
#Ceci va créer une erreur car contrainte UNIQUE sur PHONE
INSERT INTO contacts (name, phone)
VALUES ('billybob', '8781213455');
INSERT INTO contacts (name, phone)
VALUES ('Pablo', '8781213455');
##############################
#CHECK
##############################
CREATE TABLE users (
username VARCHAR(20) NOT NULL,
age INT CHECK (age > 0)
);
#OK
INSERT INTO users (username, age) VALUES ('Pablo' ,25);
#Erreur car age est négatif et la contrainte (age > 0)
INSERT INTO users (username, age) VALUES ('Pablo' ,-25);
#Autre exemple
CREATE TABLE palindromes (
word VARCHAR(100) CHECK(REVERSE(word) = word)
);
INSERT INTO palindromes (word) VALUES ('Laval');
INSERT INTO palindromes (word) VALUES ('Lol');
#Erreur
INSERT INTO palindromes (word) VALUES ('Pablo');
##############################
#Nommer une Contrainte
##############################
CREATE TABLE users2 (
username VARCHAR(20) NOT NULL,
age INT,
CONSTRAINT age_not_negative CHECK (age >= 0)
);
#OK
INSERT INTO users2 (username, age) VALUES ('Pablo' ,25);
#Erreur car age est négatif
INSERT INTO users2 (username, age) VALUES ('Pablo' ,-25);
CREATE TABLE palindromes2 (
word VARCHAR(100),
CONSTRAINT word_is_palindrome CHECK(REVERSE(word) = word)
);
INSERT INTO palindromes2 (word) VALUES ('Laval');
INSERT INTO palindromes2 (word) VALUES ('Lol');
#Erreur
INSERT INTO palindromes2 (word) VALUES ('Pablo');
##############################
#Plusieurs colonnes avec des contraintes
##############################
CREATE TABLE companies (
name VARCHAR(255) NOT NULL,
address VARCHAR(255) NOT NULL,
CONSTRAINT name_address UNIQUE (name , address)
);
INSERT INTO companies (name, address) VALUES ('blackbird', '1234 Ahuntsic');
INSERT INTO companies (name, address) VALUES ('whitebird', '1234 Ahuntsic');
#Erreur
INSERT INTO companies (name, address) VALUES ('blackbird', '1234 Ahuntsic');
#Exemple de Contrainte avec CHECK
#Contrainte qui s'assure que le prix de vente est plus élevé que le prix d'achat
CREATE TABLE houses (
purchase_price INT NOT NULL,
sale_price INT NOT NULL,
CONSTRAINT saleprice_higer_purchaseprice CHECK(sale_price >= purchase_price)
);
INSERT INTO houses (purchase_price, sale_price) VALUES (100000, 200000);
#Erreur
INSERT INTO houses (purchase_price, sale_price) VALUES (200000, 100000);¶ Introduction
En MySQL, une contrainte (constraint en anglais) est une règle définie sur une table pour restreindre les types de données ou les valeurs qui peuvent être insérées dans une ou plusieurs colonnes d'une table.
Les contraintes peuvent être appliquées lors de la création de la table ou après la création de la table, en utilisant la commande ALTER TABLE. Les contraintes sont utilisées pour garantir l'intégrité des données en empêchant les enregistrements de violer les règles définies pour la table.
Il existe plusieurs types de contraintes dans MySQL, dont les plus courantes sont :
- La contrainte de clé primaire (PRIMARY KEY) : elle permet de définir une colonne ou un groupe de colonnes comme clé primaire de la table. Cette contrainte garantit que chaque enregistrement dans la table a une valeur unique dans la colonne clé primaire.
- La contrainte de clé étrangère (FOREIGN KEY) : elle permet de lier deux tables en spécifiant une colonne ou un groupe de colonnes dans une table comme clé étrangère qui fait référence à une colonne ou un groupe de colonnes dans une autre table.
- La contrainte d'unicité (UNIQUE) : elle permet de garantir que chaque enregistrement dans une colonne ou un groupe de colonnes a une valeur unique.
- La contrainte de vérification (CHECK) : elle permet de spécifier une condition pour vérifier la validité des valeurs d'une colonne.
- La contrainte de non-nullité (NOT NULL) : elle permet de garantir que chaque enregistrement dans une colonne a une valeur.
Ces contraintes peuvent être utilisées pour garantir l'intégrité des données dans une base de données MySQL et pour assurer la cohérence des données stockées dans les tables.
À travers ces contraintes, nous assurons l'intégrité des données qui assurent la qualité et la cohérence des données dans une base de données. Les contraites mentionnées ci-haut peuvent être diviser en 3 principaux concepts:
Contraintes d'intégrité d'entité
- PRIMARY KEY (clé primaire unique et non nulle)
- NOT NULL (valeur obligatoire)
- UNIQUE (valeur unique)
Contraintes d'intégrité référentielle
- FOREIGN KEY (clé étrangère)
- ON DELETE/UPDATE (actions en cascade)
- Assure la cohérence entre les tables liées
Contraintes d'intégrité de domaine
- CHECK (vérifie une condition)
- DEFAULT (valeur par défaut)
- Type de données (INT, VARCHAR, etc.)
CREATE TABLE etudiants (
id INT AUTO_INCREMENT, -- Intégrité d'entité
nom VARCHAR(50) NOT NULL, -- Intégrité de domaine
email VARCHAR(100) UNIQUE, -- Intégrité d'entité
age INT CHECK (age >= 18), -- Intégrité de domaine
classe_id INT, -- Intégrité référentielle
status VARCHAR(20) DEFAULT 'actif', -- Intégrité de domaine
PRIMARY KEY (id),
FOREIGN KEY (classe_id) REFERENCES classes(id)
ON DELETE CASCADE
);¶ UNIQUE
Lorsque vous créez une table dans MySQL, vous pouvez ajouter une contrainte UNIQUE sur une ou plusieurs colonnes pour garantir que chaque valeur de ces colonnes est unique dans la table. La contrainte UNIQUE empêche l'insertion de valeurs en double dans les colonnes spécifiées. Voici la syntaxe pour ajouter une contrainte UNIQUE lors de la création d'une table :
CREATE TABLE table_name (
column1 datatype UNIQUE,
column2 datatype,
...
);
Il est important de noter que la contrainte UNIQUE s'applique à chaque valeur individuelle dans les colonnes spécifiées, et non à la combinaison de valeurs dans toutes les colonnes de la table. Cela signifie que vous pouvez avoir des doublons si une colonne a la même valeur dans plusieurs lignes, mais les autres colonnes ont des valeurs différentes.
¶ CHECK
Dans MySQL, la clause CHECK est utilisée pour ajouter une condition à une colonne de table. La condition spécifiée dans la clause CHECK est vérifiée lors de l'insertion ou de la mise à jour de données dans la table.
Supposons que vous souhaitez créer une table "Personnes" dans laquelle vous stockez les noms et les âges des personnes. Vous souhaitez vous assurer que l'âge d'une personne est toujours compris entre 18 et 65 ans. Voici comment vous pouvez utiliser la clause CHECK pour définir cette condition :
CREATE TABLE Personnes (
id INT PRIMARY KEY,
nom VARCHAR(50) NOT NULL,
age INT CHECK (age >= 18 AND age <= 65)
);
Dans cet exemple, la clause CHECK est utilisée pour spécifier que la valeur de la colonne "age" doit être supérieure ou égale à 18 et inférieure ou égale à 65. Lorsque vous insérez ou mettez à jour des données dans la table "Personnes", la base de données vérifiera si la condition est respectée avant d'accepter les données.
¶ Nommage
Lorsqu’une contrainte est violée, un message d’erreur apparaît:

Nous pouvons personnaliser le message affiché lors de la création de la table. Par exemple:
CREATE TABLE palindromes2 (
word VARCHAR(100),
CONSTRAINT word_is_palindrome CHECK(REVERSE(word) = word)
);

¶ Contrainte sur plusieurs colonnes
Il est possible de créer une contrainte qui porte sur plusieurs colonnes d'une même table. Pour cela, vous pouvez utiliser la syntaxe suivante lors de la création de la contrainte :
CREATE TABLE nom_table (
colonne1 datatype NOT NULL,
colonne2 datatype NOT NULL,
CONSTRAINT nom_contrainte UNIQUE (colonne1, colonne2)
);
Dans cet exemple, la contrainte nommée "nom_contrainte" est créée sur les colonnes "colonne1" et "colonne2" de la table "nom_table". Cette contrainte garantit que les valeurs de ces deux colonnes seront uniques ensembles, c'est-à-dire qu'il ne peut y avoir deux lignes avec les mêmes valeurs pour ces deux colonnes à la fois.
Il est également possible de créer des contraintes portant sur plusieurs colonnes avec d'autres types de contraintes, telles que les clés étrangères ou les contraintes de vérification (CHECK).
¶ Alter Tables
¶ Script
-- Création de la table initiale
CREATE TABLE employees (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100)
);
-- 1. AJOUTER UNE COLONNE
-- Ajoute une colonne 'hire_date' à la table
ALTER TABLE employees
ADD COLUMN hire_date DATE;
-- 2. AJOUTER PLUSIEURS COLONNES
-- Ajoute deux nouvelles colonnes: salaire et département
ALTER TABLE employees
ADD COLUMN salary DECIMAL(10,2),
ADD COLUMN department VARCHAR(50);
-- 3. SUPPRIMER UNE COLONNE
-- Supprime la colonne email
ALTER TABLE employees
DROP COLUMN email;
-- 4. MODIFIER LE TYPE D'UNE COLONNE
-- Change la taille du champ department
ALTER TABLE employees
MODIFY COLUMN department VARCHAR(100);
-- 5. RENOMMER UNE COLONNE
-- Renomme first_name en firstname
ALTER TABLE employees
CHANGE COLUMN first_name firstname VARCHAR(50);
-- 6. AJOUTER UNE CLÉ ÉTRANGÈRE
-- D'abord, créons une table departments
CREATE TABLE departments (
dept_id INT PRIMARY KEY,
dept_name VARCHAR(50)
);
-- Puis ajoutons la clé étrangère
ALTER TABLE employees
ADD CONSTRAINT fk_department
FOREIGN KEY (department) REFERENCES departments(dept_name);
-- 7. SUPPRIMER UNE CLÉ ÉTRANGÈRE
ALTER TABLE employees
DROP FOREIGN KEY fk_department;
-- 8. AJOUTER UN INDEX
ALTER TABLE employees
ADD INDEX idx_lastname (last_name);
-- 9. SUPPRIMER UN INDEX
ALTER TABLE employees
DROP INDEX idx_lastname;
-- 10. MODIFIER LA VALEUR PAR DÉFAUT D'UNE COLONNE
ALTER TABLE employees
ALTER COLUMN department SET DEFAULT 'Non assigné';
-- 11. SUPPRIMER LA VALEUR PAR DÉFAUT
ALTER TABLE employees
ALTER COLUMN department DROP DEFAULT;
-- 12. RENOMMER LA TABLE
ALTER TABLE employees
RENAME TO staff;
-- 13. AJOUTER UNE CONTRAINTE UNIQUE
ALTER TABLE employees
ADD CONSTRAINT uc_email UNIQUE (email);
-- 14. SUPPRIMER UNE CONTRAINTE UNIQUE
ALTER TABLE employees
DROP INDEX uc_email;
-- 15. AJOUTER UNE CONTRAINTE CHECK
ALTER TABLE employees
ADD CONSTRAINT chk_salary CHECK (salary > 0);¶ Introduction
ALTER TABLE est une instruction SQL qui permet de modifier la structure d'une table existante dans une base de données. Cette instruction est souvent utilisée lorsque vous devez ajouter, supprimer ou modifier des colonnes dans une table, ou encore pour changer les contraintes ou les propriétés de la table. Voici quelques exemples:
Ajouter une colonne à une table existante:
ALTER TABLE nom_table ADD nom_colonne type_colonne;Supprimer une colonne d’une table existante:
ALTER TABLE nom_table DROP COLUMN nom_colonne;Modifier le type de données d’une colonne:
ALTER TABLE nom_table ALTER COLUMN nom_colonne type_colonne;
ALTER TABLE nom_table MODIFY COLUMN nom_colonne type_colonne;
ALTER TABLE nom_table CHANGE nom_colonne nouveau_nom_colonne nouveau_type_colonne;Modifier le nom d’une table:
ALTER TABLE nom_table RENAME TO nouveau_nom_table;Renommer une colonne
ALTER TABLE nom_colonne RENAME COLUMN TO nouveau_nom_colonne;
Pour plus d'nformation sur la commande ALTER TABLE: https://dev.mysql.com/doc/refman/8.0/en/alter-table.html

¶ Jointures
¶ Définition
Une jointure est une opération SQL qui permet de combiner des lignes de deux ou plusieurs tables selon une condition de correspondance entre leurs colonnes. Les jointures sont utilisées pour plusieurs raisons essentielles :
1. Pour éviter la redondance des données
- Au lieu de tout stocker dans une seule table gigantesque
- Les données sont réparties dans différentes tables liées entre elles
- Exemple : stocker les informations d'un client une seule fois, même s'il a plusieurs commandes
2. Pour obtenir des informations complètes
- Récupérer des données qui sont réparties dans différentes tables
- Exemple : avoir le nom du client avec sa commande, alors que ces infos sont dans deux tables différentes
3. Pour maintenir l'intégrité des données
- Les données sont mieux organisées et plus faciles à mettre à jour
- On évite les incohérences dans la base de données
-- Sans jointure (une seule grosse table)
CREATE TABLE commandes_complete (
id INT,
date DATE,
client_nom VARCHAR(100),
client_email VARCHAR(100),
client_adresse TEXT,
produit_nom VARCHAR(100),
produit_prix DECIMAL(10,2)
);
-- Avec jointures (3 tables distinctes liées)
CREATE TABLE clients (
id INT,
nom VARCHAR(100),
email VARCHAR(100),
adresse TEXT
);
CREATE TABLE commandes (
id INT,
date DATE,
client_id INT
);
CREATE TABLE produits (
id INT,
nom VARCHAR(100),
prix DECIMAL(10,2)
);¶ Exemple de la vie concrète
Le chef d’un restaurant vous demande de stocker les commandes de chacun de ses clients afin de pouvoir faire de statistiques plus tard. Nous voulons stoker:
- Le nom et le prénom du client
- Le courriel du client
- La date d’achat de la commande
- Le prix d’achat de la commande

¶ Votre solution
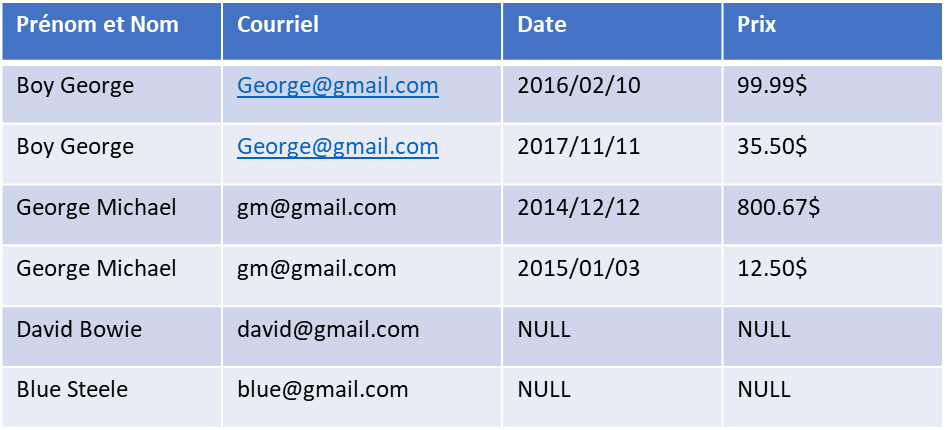
Redondance de l’information
La table va grossir rapidement
Solution non optimale (mauvaise segmentation)
Certains champs ne sont pas à leur expression la plus simple
¶ Meilleure solution
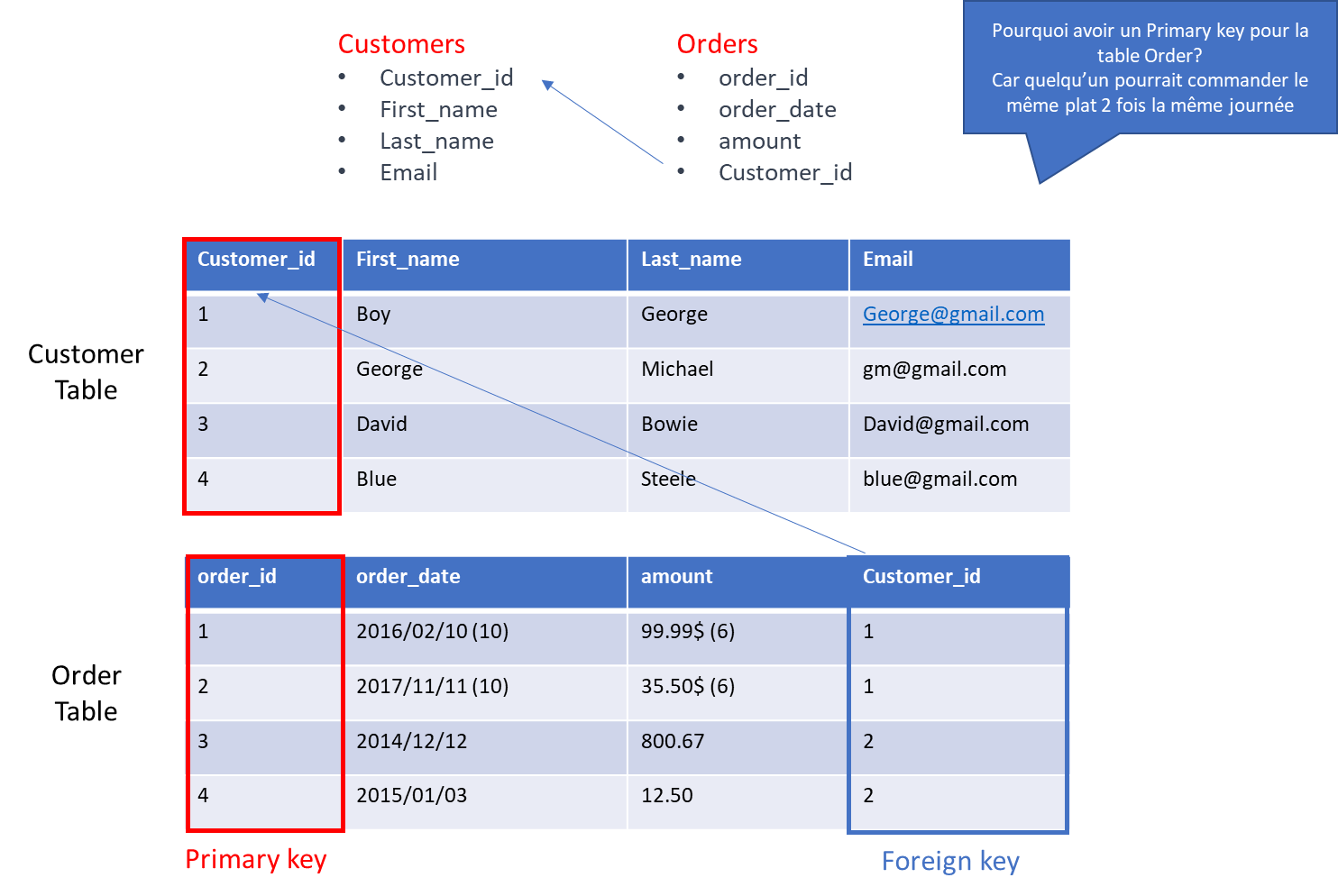
Pour rappel:
Une clé primaire (PRIMARY KEY) est un champ ou un ensemble de champs qui identifie de manière unique chaque enregistrement dans une table MySQL, et ne peut contenir de valeur NULL.
Une clé étrangère (FOREIGN KEY) est une colonne qui établit une relation entre deux tables en faisant référence à la clé primaire d'une autre table pour maintenir l'intégrité référentielle des données.
Une table peut avoir un clé primaire et étrangère
¶ Les relations
Une relation dans MySQL est un lien logique entre deux ou plusieurs tables qui permet de représenter et maintenir les associations entre les données, qu'elles soient de type un-à-un (one-to-one), un-à-plusieurs (one-to-many) ou plusieurs-à-plusieurs (many-to-many), en utilisant des clés primaires et étrangères pour assurer l'intégrité référentielle.
¶ ONE to ONE
Dans une base de données relationnelle, une relation One-to-One (un-à-un) est une relation où chaque enregistrement dans la table source est associé à un seul enregistrement dans la table cible, et vice versa.
Par exemple, supposons que nous avons deux tables : "utilisateurs" et "informations_personnelles". La table "utilisateurs" stocke des informations telles que l'identifiant d'utilisateur, le nom d'utilisateur et le mot de passe, tandis que la table "informations_personnelles" stocke des informations personnelles sur chaque utilisateur, telles que le nom complet, l'adresse, le numéro de téléphone, etc.
Pour créer une relation One-to-One entre ces deux tables, nous pourrions ajouter une colonne "user_id" à la table "informations_personnelles", qui correspondrait à l'identifiant d'utilisateur dans la table "utilisateurs". De cette façon, chaque enregistrement dans la table "utilisateurs" serait associé à un seul enregistrement dans la table "informations_personnelles" (à condition que les enregistrements existent dans les deux tables).
Cela peut être utile dans des situations où nous souhaitons séparer les données personnelles sensibles de l'information d'identification de l'utilisateur, tout en conservant un lien entre les deux tables pour permettre des requêtes plus avancées.

-- Création de la table Students
CREATE TABLE Students (
Student_ID INT PRIMARY KEY,
Last_Name VARCHAR(50) NOT NULL,
First_Name VARCHAR(50) NOT NULL
);
-- Création de la table Contact_Info
CREATE TABLE Contact_Info (
Student_ID INT PRIMARY KEY,
City VARCHAR(100),
Phone VARCHAR(20),
FOREIGN KEY (Student_ID) REFERENCES Students(Student_ID)
);
-- Exemple d'insertion des données montrées dans l'image
INSERT INTO Students (Student_ID, Last_Name, First_Name)
VALUES (12345, 'Tang', 'Sophie');
INSERT INTO Contact_Info (Student_ID, City, Phone)
VALUES (12345, 'New York', '408-555-3456');¶ ONE to MANY
Dans une base de données relationnelle, une relation One-to-Many (un-à-plusieurs) est une relation où chaque enregistrement dans la table source est associé à plusieurs enregistrements dans la table cible, mais chaque enregistrement dans la table cible n'est associé qu'à un seul enregistrement dans la table source.
Par exemple, supposons que nous avons deux tables : "clients" et "commandes". La table "clients" stocke des informations sur chaque client, telles que le nom, l'adresse, le numéro de téléphone, etc., tandis que la table "commandes" stocke des informations sur chaque commande, telles que la date de commande, le montant total, etc.
Pour créer une relation One-to-Many entre ces deux tables, nous pourrions ajouter une colonne "client_id" à la table "commandes", qui correspondrait à l'identifiant du client dans la table "clients". De cette façon, chaque enregistrement dans la table "clients" serait associé à plusieurs enregistrements dans la table "commandes", mais chaque enregistrement dans la table "commandes" ne serait associé qu'à un seul enregistrement dans la table "clients".
Cela permet de maintenir une trace des commandes de chaque client tout en conservant les informations de base des clients dans une table séparée. Lorsqu'on veut récupérer des informations de clients avec toutes leurs commandes, on peut utiliser une jointure (JOIN) pour combiner les deux tables sur la base de leur relation One-to-Many.
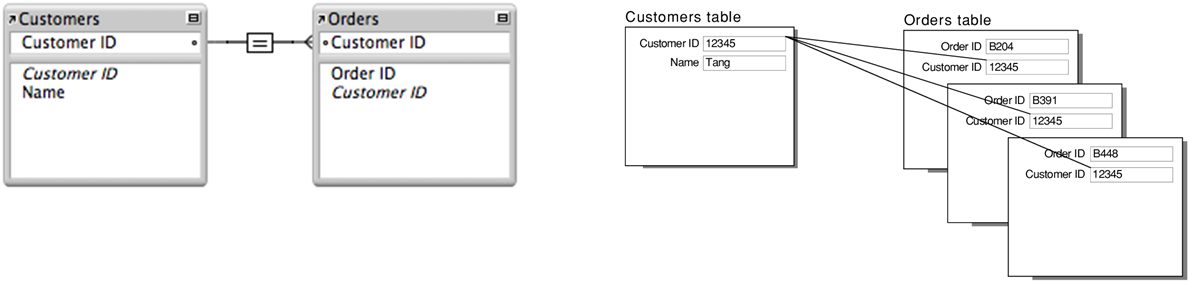
-- Création de la table Customers
CREATE TABLE Customers (
Customer_ID INT PRIMARY KEY,
Name VARCHAR(100) NOT NULL
);
-- Création de la table Orders
CREATE TABLE Orders (
Order_ID VARCHAR(10) PRIMARY KEY,
Customer_ID INT,
FOREIGN KEY (Customer_ID) REFERENCES Customers(Customer_ID)
);
-- Exemple d'insertion des données montrées dans l'image
INSERT INTO Customers (Customer_ID, Name)
VALUES (12345, 'Tang');
INSERT INTO Orders (Order_ID, Customer_ID)
VALUES
('B204', 12345),
('B391', 12345),
('B448', 12345);¶ MANY to MANY
Dans une base de données relationnelle, une relation Many-to-Many (plusieurs-à-plusieurs) est une relation où chaque enregistrement dans la table source peut être associé à plusieurs enregistrements dans la table cible, et vice versa.
Par exemple, supposons que nous avons deux tables : "étudiants" et "cours". La table "étudiants" stocke des informations sur chaque étudiant, telles que le nom, l'adresse, le numéro de téléphone, etc., tandis que la table "cours" stocke des informations sur chaque cours, telles que le titre, la description, etc.
Pour créer une relation Many-to-Many entre ces deux tables, nous aurions besoin d'une troisième table appelée une table de jonction ou une table d'association. Cette table contiendrait au moins deux colonnes : une colonne "étudiant_id" qui correspondrait à l'identifiant de l'étudiant dans la table "étudiants", et une colonne "cours_id" qui correspondrait à l'identifiant du cours dans la table "cours".
Chaque enregistrement dans la table de jonction représenterait une relation entre un étudiant et un cours. Ainsi, un étudiant pourrait être associé à plusieurs cours, et un cours pourrait être associé à plusieurs étudiants.
Lorsqu'on souhaite récupérer les cours suivis par un étudiant donné, on peut utiliser une jointure (JOIN) entre la table "étudiants" et la table de jonction, puis une autre jointure entre la table de jonction et la table "cours". De même, lorsqu'on souhaite récupérer les étudiants suivant un cours donné, on peut utiliser une jointure entre la table "cours" et la table de jonction, puis une autre jointure entre la table de jonction et la table "étudiants". En résumé, la relation Many-to-Many est utile pour modéliser des situations où plusieurs enregistrements d'une table peuvent être associés à plusieurs enregistrements d'une autre table.
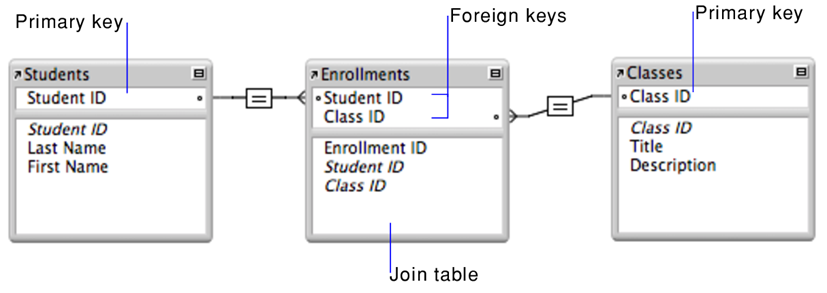
-- Création de la table Students
CREATE TABLE Students (
Student_ID INT PRIMARY KEY,
Last_Name VARCHAR(50) NOT NULL,
First_Name VARCHAR(50) NOT NULL
);
-- Création de la table Classes
CREATE TABLE Classes (
Class_ID INT PRIMARY KEY,
Title VARCHAR(100) NOT NULL,
Description TEXT
);
-- Création de la table de jonction Enrollments
CREATE TABLE Enrollments (
Enrollment_ID INT PRIMARY KEY AUTO_INCREMENT,
Student_ID INT,
Class_ID INT,
FOREIGN KEY (Student_ID) REFERENCES Students(Student_ID),
FOREIGN KEY (Class_ID) REFERENCES Classes(Class_ID)
);
-- Insertion d'exemples de données
INSERT INTO Students (Student_ID, Last_Name, First_Name) VALUES
(1, 'Dupont', 'Marie'),
(2, 'Martin', 'Lucas'),
(3, 'Bernard', 'Sophie');
INSERT INTO Classes (Class_ID, Title, Description) VALUES
(101, 'Mathématiques', 'Cours de mathématiques avancées'),
(102, 'Physique', 'Introduction à la physique'),
(103, 'Informatique', 'Programmation en Java');
-- Inscriptions des étudiants aux cours
INSERT INTO Enrollments (Student_ID, Class_ID) VALUES
(1, 101), -- Marie suit les maths
(1, 102), -- Marie suit la physique
(2, 101), -- Lucas suit les maths
(2, 103), -- Lucas suit l'informatique
(3, 102), -- Sophie suit la physique
(3, 103); -- Sophie suit l'informatique
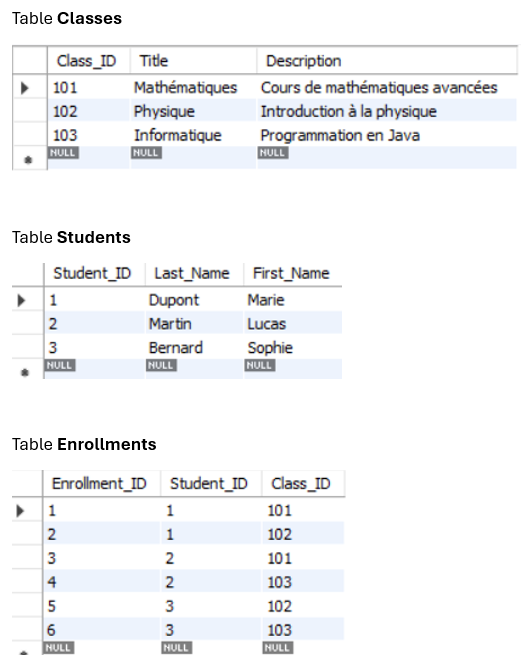
La jointure de ces tables donnera le résutat suivant:
-- Jointure des trois tables pour voir toutes les inscriptions
SELECT
s.Student_ID,
CONCAT(s.First_Name, ' ', s.Last_Name) AS Student_Name,
c.Class_ID,
c.Title AS Class_Name,
e.Enrollment_ID
FROM Students s
JOIN Enrollments e ON s.Student_ID = e.Student_ID
JOIN Classes c ON e.Class_ID = c.Class_ID
ORDER BY s.Student_ID, c.Class_ID;
/*
Résultat attendu:
+------------+--------------+----------+---------------+--------------+
|Student_ID |Student_Name |Class_ID |Class_Name |Enrollment_ID |
+------------+--------------+----------+---------------+--------------+
|1 |Marie Dupont |101 |Mathématiques |1 |
|1 |Marie Dupont |102 |Physique |2 |
|2 |Lucas Martin |101 |Mathématiques |3 |
|2 |Lucas Martin |103 |Informatique |4 |
|3 |Sophie Bernard|102 |Physique |5 |
|3 |Sophie Bernard|103 |Informatique |6 |
+------------+--------------+----------+---------------+--------------+
*/¶ Exemples de relations
- Auteur et livres
- Lecteur et commandes
- Livre et reviews
- Lecteur et reviews
- Auteurs et livres
- Livre et genres
- Commande et livres
¶ Types de jointures
Dans MySQL, une jointure (ou JOIN en anglais) est une opération qui permet de combiner les données de deux ou plusieurs tables en utilisant une clé commune. L'objectif principal de la jointure est de récupérer des données qui ne peuvent pas être obtenues à partir d'une seule table. En d’autres mots, les jointures sont utilisées pour combiner des lignes de deux ou plusieurs tables, en fonction d'une colonne commune entre elles. Les types de jointures les plus courants sont :
- INNER JOIN: Cette jointure renvoie les enregistrements qui ont des correspondances dans les deux tables. C'est-à-dire que seuls les enregistrements ayant une correspondance dans les deux tables sont renvoyés.
- LEFT JOIN: Cette jointure renvoie tous les enregistrements de la table de gauche (ou la première table mentionnée dans la commande) et les enregistrements correspondants de la table de droite (ou la deuxième table mentionnée dans la commande). Si un enregistrement de la table de gauche n'a pas de correspondance dans la table de droite, les colonnes de la table de droite sont remplies avec des valeurs NULL.
- RIGHT JOIN: Cette jointure est similaire à LEFT JOIN, mais elle renvoie tous les enregistrements de la table de droite et les enregistrements correspondants de la table de gauche. Si un enregistrement de la table de droite n'a pas de correspondance dans la table de gauche, les colonnes de la table de gauche sont remplies avec des valeurs NULL.
- OUTER JOIN: Cette jointure renvoie tous les enregistrements des deux tables, avec des valeurs NULL pour les colonnes qui n'ont pas de correspondance dans l'autre table. Cette jointure n'existe pas dans MySQL mais peut être simulée par un LEFT JOIN + RIGHT JOIN + UNION.
- CROSS JOIN: Cette jointure retourne le produit cartésien des deux tables, c'est-à-dire toutes les combinaisons possibles de lignes entre les deux tables. Elle est rarement utilisée dans la pratique car elle peut produire un très grand nombre de lignes.
- UNION: Une UNION est une opération SQL qui combine les résultats de deux ou plusieurs requêtes SELECT en un seul ensemble de résultats en éliminant les doublons.
La syntaxe générale pour effectuer une jointure en MySQL est la suivante:
SELECT colonnes
FROM table1
JOIN table2 ON condition;
Dans cette syntaxe, colonnes est la liste des colonnes que vous souhaitez sélectionner, table1 et table2 sont les noms des tables que vous souhaitez joindre, et condition est la clause qui spécifie la condition de jointure. La condition de jointure est généralement une expression qui compare les valeurs d'une colonne dans chaque table.
¶ Explication graphique
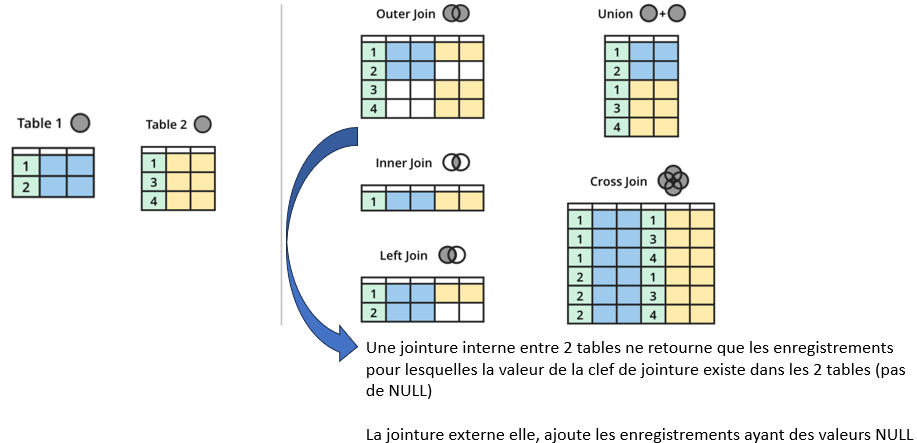
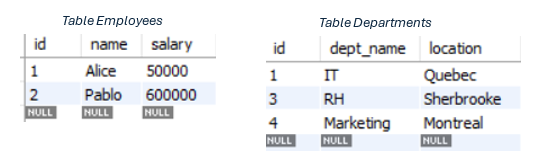
-- Création des tables
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
salary INT
);
CREATE TABLE departments (
id INT PRIMARY KEY,
dept_name VARCHAR(50),
location VARCHAR(50)
);
-- Insertion des données exactes
INSERT INTO employees (id, name, salary) VALUES
(1, 'Alice', 50000),
(2, 'Pablo', 600000);
INSERT INTO departments (id, dept_name, location) VALUES
(1, 'IT', 'Quebec'),
(3, 'RH', 'Sherbrooke'),
(4, 'Marketing', 'Montreal');
-- 1. INNER JOIN
SELECT e.*, d.*
FROM employees e
INNER JOIN departments d ON e.id = d.id;
-- 2. LEFT JOIN
SELECT e.*, d.*
FROM employees e
LEFT JOIN departments d ON e.id = d.id;
-- 3. RIGHT JOIN
SELECT e.*, d.*
FROM employees e
RIGHT JOIN departments d ON e.id = d.id;
-- 4. OUTER JOIN (FULL OUTER JOIN simulé avec UNION)
SELECT e.*, d.*
FROM employees e
LEFT JOIN departments d ON e.id = d.id
UNION
SELECT e.*, d.*
FROM employees e
RIGHT JOIN departments d ON e.id = d.id;
-- 5. CROSS JOIN
SELECT e.*, d.*
FROM employees e
CROSS JOIN departments d;
-- 6. UNION
SELECT *
FROM employees e
UNION
SELECT *
FROM departments d
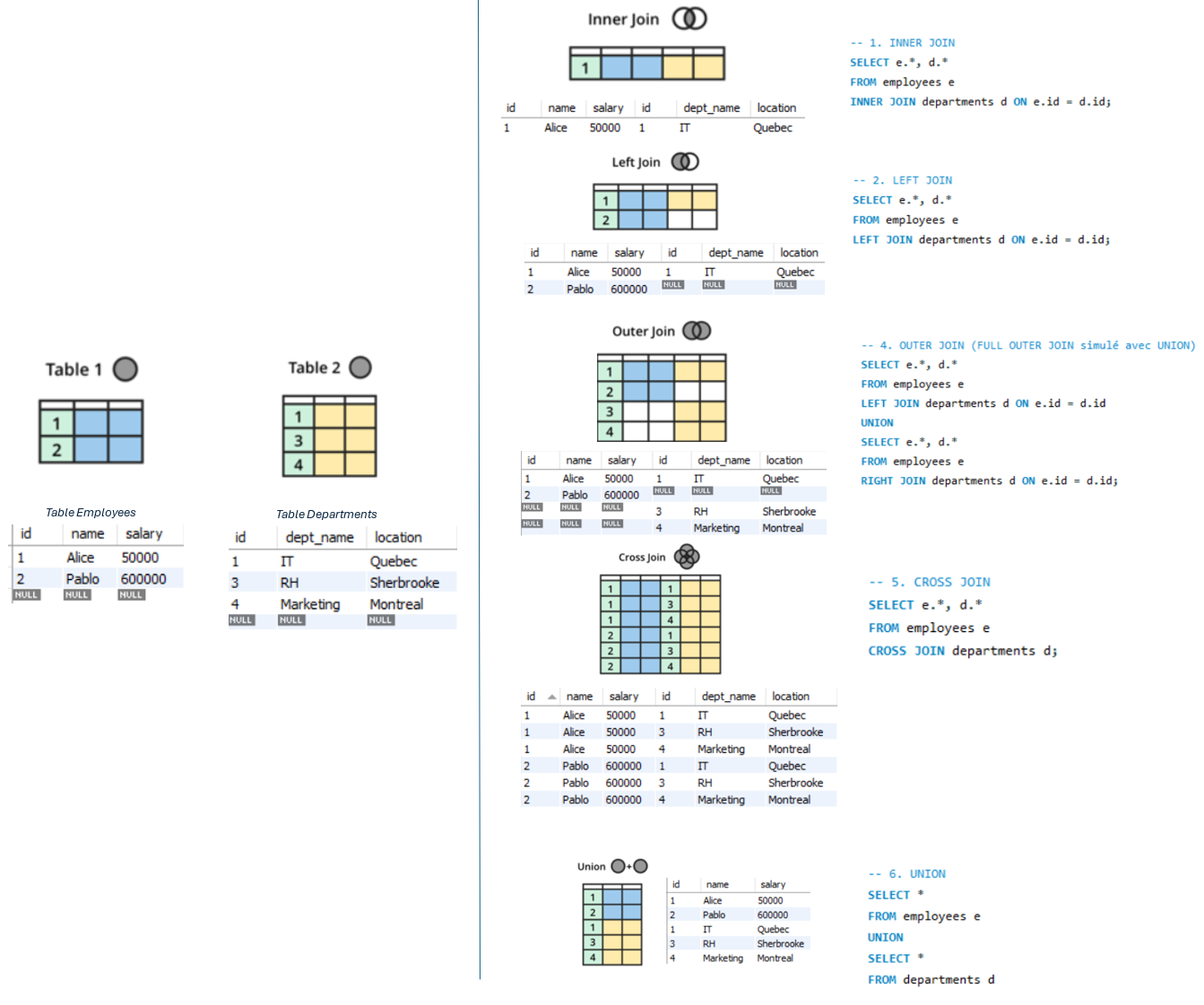
¶ Les jointures possibles
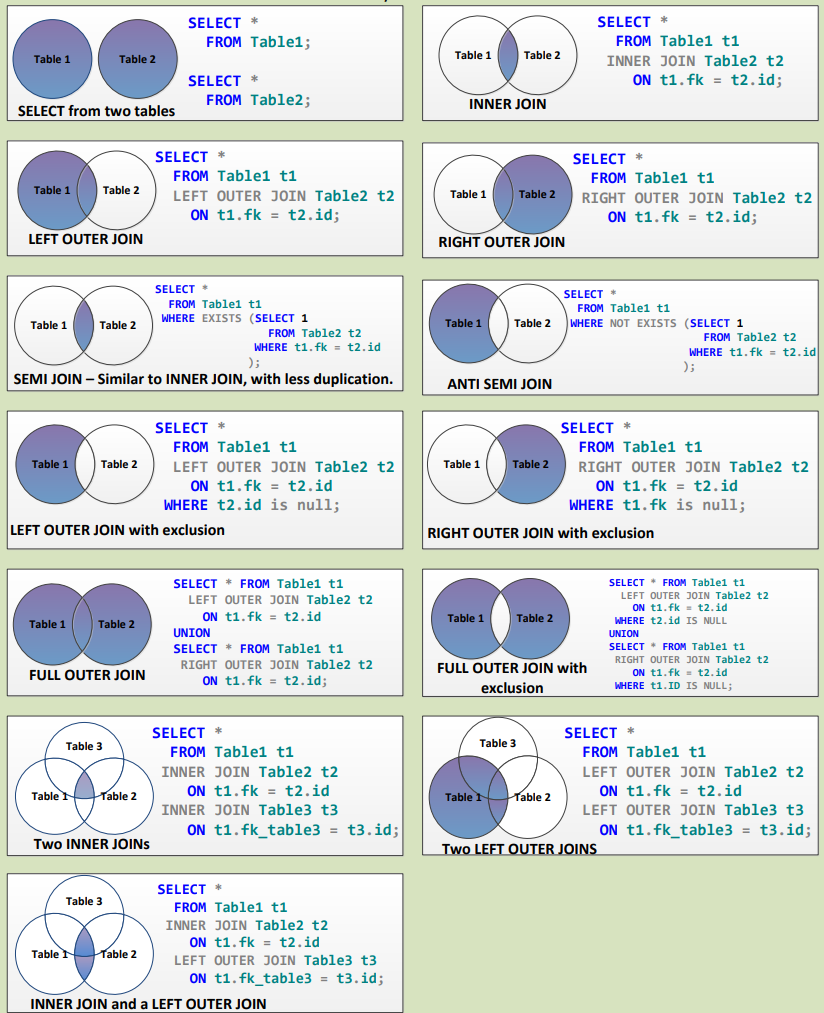

Conseils pratiques :
- Toujours utiliser des clés étrangères appropriées
- Indexer les colonnes utilisées dans les jointures
- Éviter les jointures inutiles
- Préférer INNER JOIN quand possible (meilleures performances)